nf-core/deepmutscan
nf-core/deepmutscan is a reproducible, scalable, and community-curated pipeline for analyzing deep mutational scanning (DMS) data using shotgun DNA sequencing.
Introduction
The directories listed below will be created in the results directory after nf-core/deepmutscan has finished. All paths are relative to the top-level results directory:
Every sample-specific output is grouped under a per-sample parent folder (<sample>/, the sample column of the samplesheet). Files derived from the reference (shared across all samples) live in reference/, and genuinely global reports at the top level:
results/├── <sample>/ # everything belonging to one biological sample│ ├── fastqc/ # raw sequencing QC reports for this sample's fastq files│ ├── intermediate_files/ # alignments, raw / pre-filtered / error-corrected variant count tables│ ├── library_QC/ # per-replicate QC visualisations + the error-correction report│ ├── fitness/ # merged counts, fitness + error estimates, heatmaps, DiMSum / mutscan│ └── variant_effect_inspection_tool/ # interactive HTML tool (only with --pdb)├── reference/ # reference-derived, shared: BWA index, aa_seq.txt, possible_mutations.csv├── experimental_design/ # run-level DiMSum experimental design (from the whole samplesheet)├── multiqc/ # shared raw sequencing QC report for all fastq files├── pipeline_info/ # Nextflow helper files, timeline and summary report├── timeline.html└── report.htmlFastQC
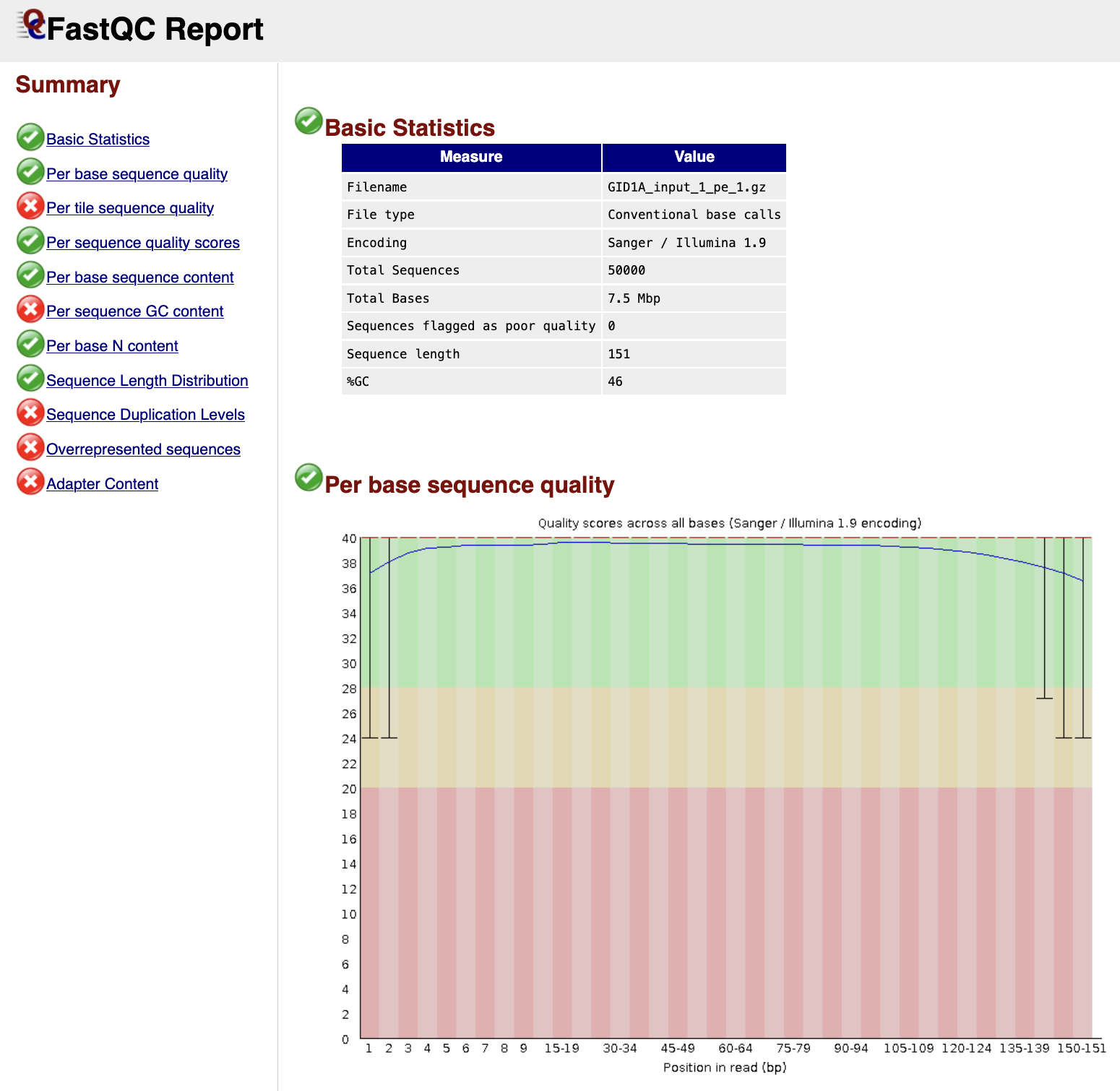
FastQC gives general quality metrics about your sequenced reads. It provides information about the quality score distribution across your reads, per base sequence content (%A/T/G/C), adapter contamination and overrepresented sequences. For further reading and documentation see the FastQC help pages.
Output files
fastqc/*_fastqc.zip: Zip archive containing the FastQC report, tab-delimited data file and plot images*_fastqc.html: FastQC report containing quality metrics
MultiQC
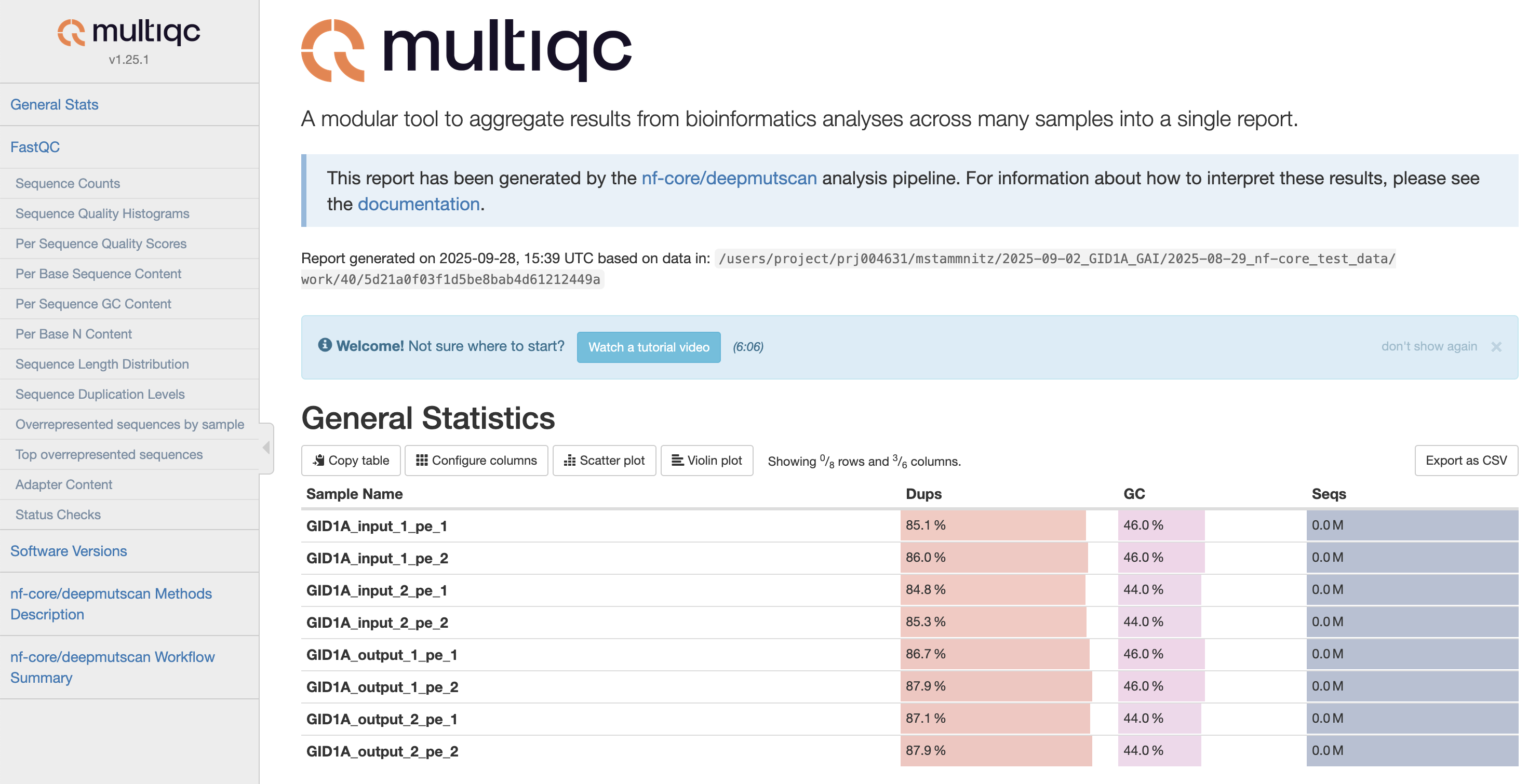
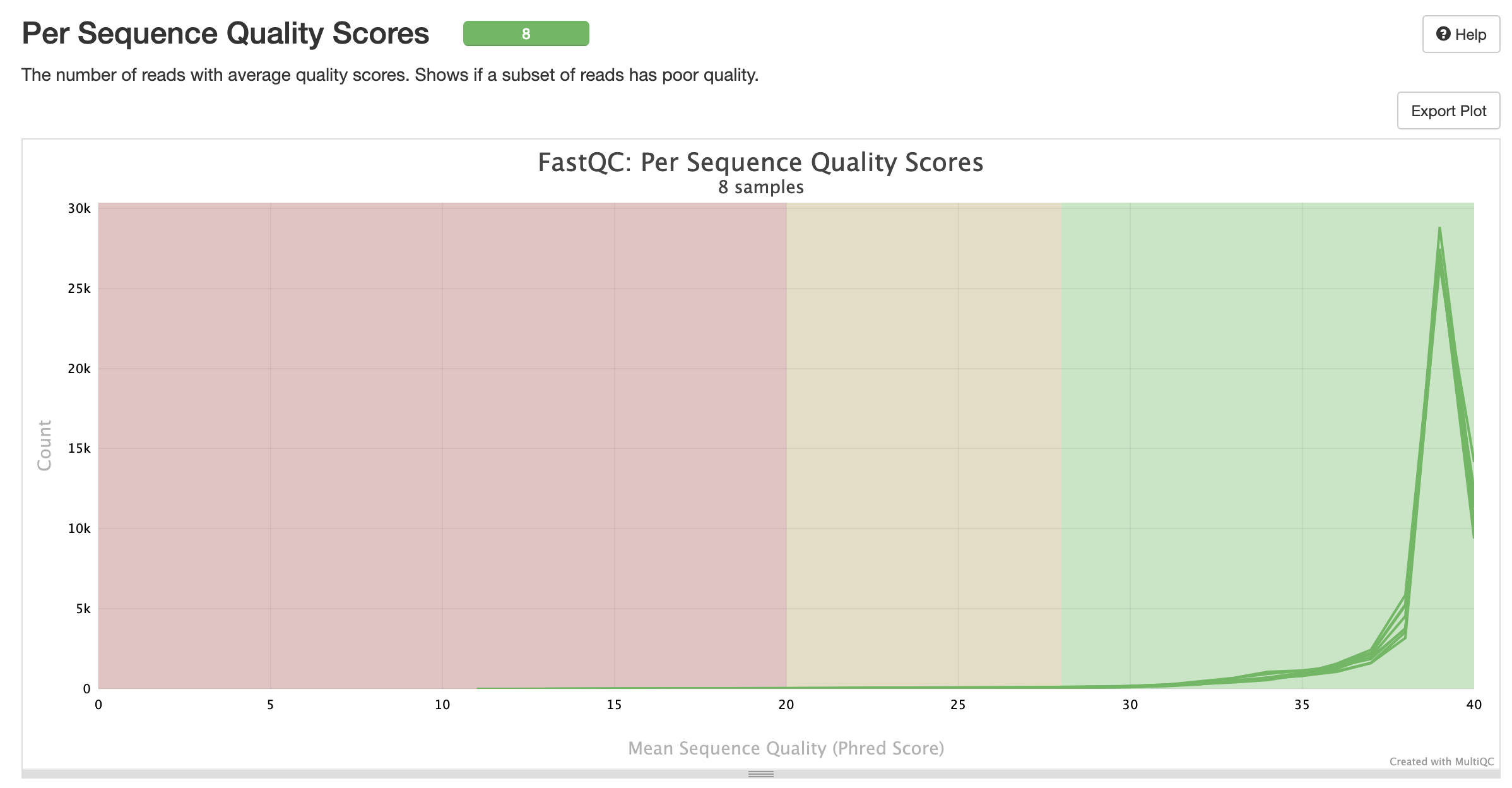
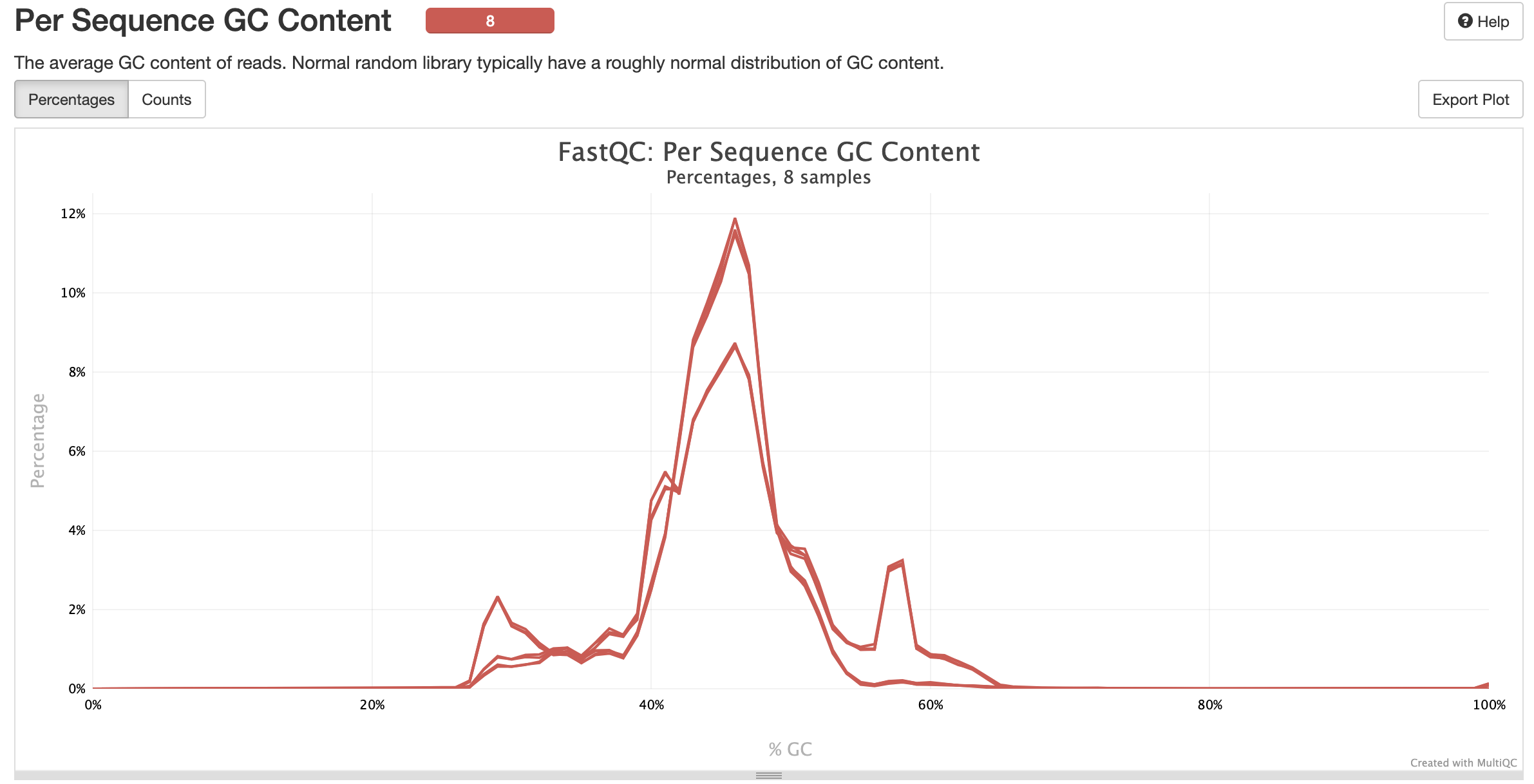
MultiQC is a visualization tool that generates a single HTML report summarising all samples in your project. Most of the pipeline QC results are visualised in the report and further statistics are available in the report data directory. Results generated by MultiQC collate pipeline QC from supported tools e.g. FastQC. The pipeline has special steps which also allow the software versions to be reported in the MultiQC output for future traceability. For more information about how to use MultiQC reports, see http://multiqc.info.### Pipeline information
Output files
multiqc/multiqc_report.html: a standalone.htmlfile that can be viewed in your web browsermultiqc_data/: directory containing parsed statistics from the different tools used in the pipelinemultiqc_plots/: directory containing static images from the report in various formats
Intermediate files (Core Pipeline Stages 1-4)
This directory is created during the first series of steps of the pipeline, featuring raw read alignments, filtering and variant counting.
Output files
intermediate_files/aa_seq.txt: a string of the reconstructed wildtype amino acid sequence of the specified open reading framepossible_mutations.csv: using the--mutagenesisargument, this file lists all the programmed mutations per position; these are used for variant count filtering and visualisationbam_files/bwa/: sets of BWA referenes indices from the original alignment(s), with BAM files for each sample in themem/subfolderbam_files/filtered/: filtered BAM files for each sample, without indel-matching reads (wildtype reads are retained for downstream sequencing-error correction)bam_files/premerged/: filtered, read-merged and re-aligned BAM files for each sample, representing highest-quality alignments for subsequent variant countingbam_files/sorted/: coordinate-sorted and indexed premerged BAM files (required by the variant counter)variant_counts/: subfolders with the resulting variant count table (*.variant_counts.tsv) plus avariant_counts_columns.tsvcolumn-description sheet, stratified by sampleprocessed_variant_counts/: subfolders with prefiltered variant count tables, stratified by sample
Library QC (Core Pipeline Stage 5)
This directory is created during the second series of steps of the pipeline, featuring various QC visualisations for each sample.
Output files
library_QC/-
counts_heatmap.pdf: a complete heatmap of absolute mutant counts, stratified by mutant amino acid (Y-axis) per position (X-axis)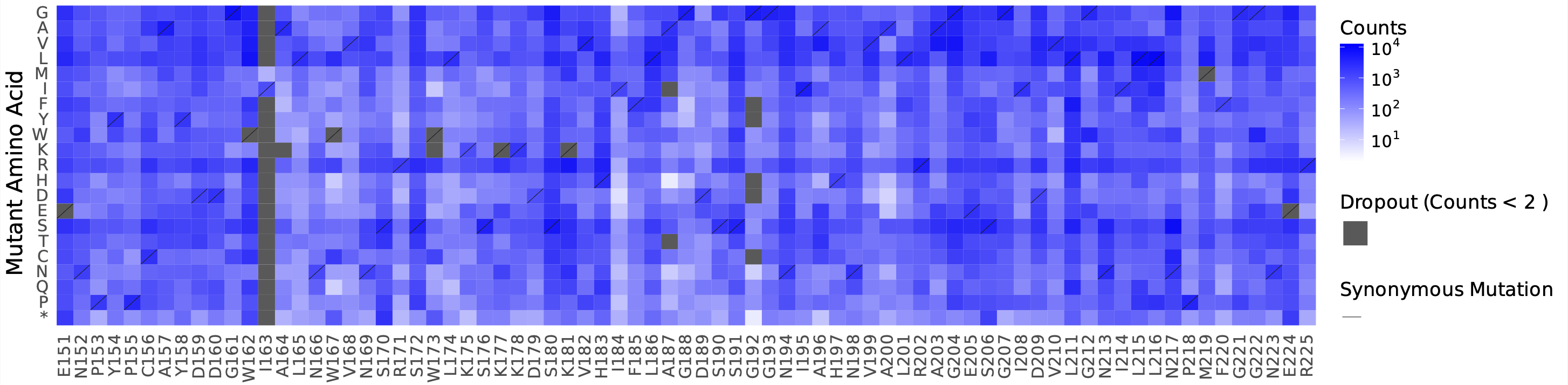
-
counts_per_cov_heatmap.pdf: as above, but as a fraction of the total sequencing coverage -
logdiff_plot.pdf: sorted, log-scale coverage distribution of all mutants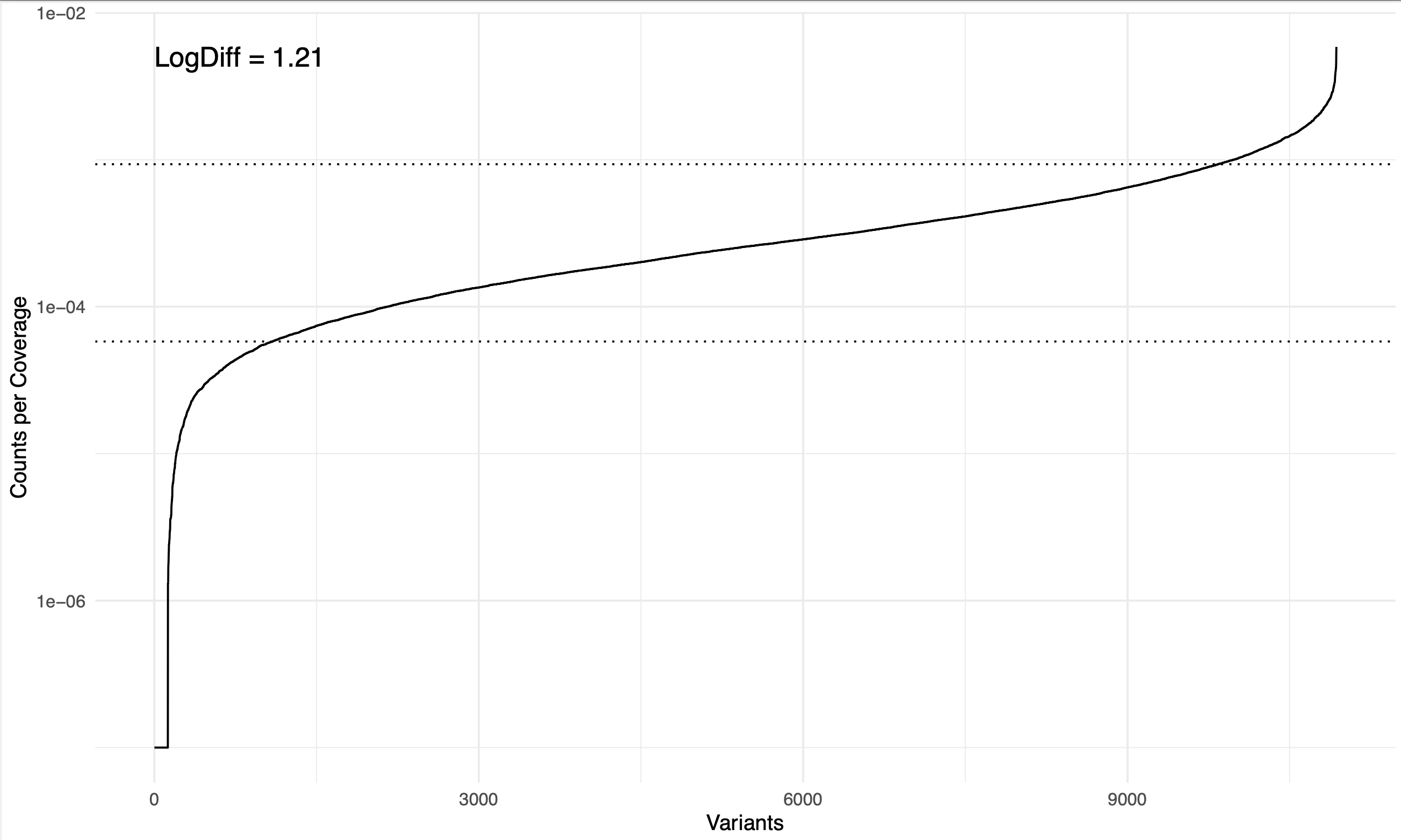
-
logdiff_varying_bases.pdf: as above, but stratified by hamming distance to the wildtype nucleotide sequence (colour shading) -
rolling_coverage.pdf: sliding-window rolling coverage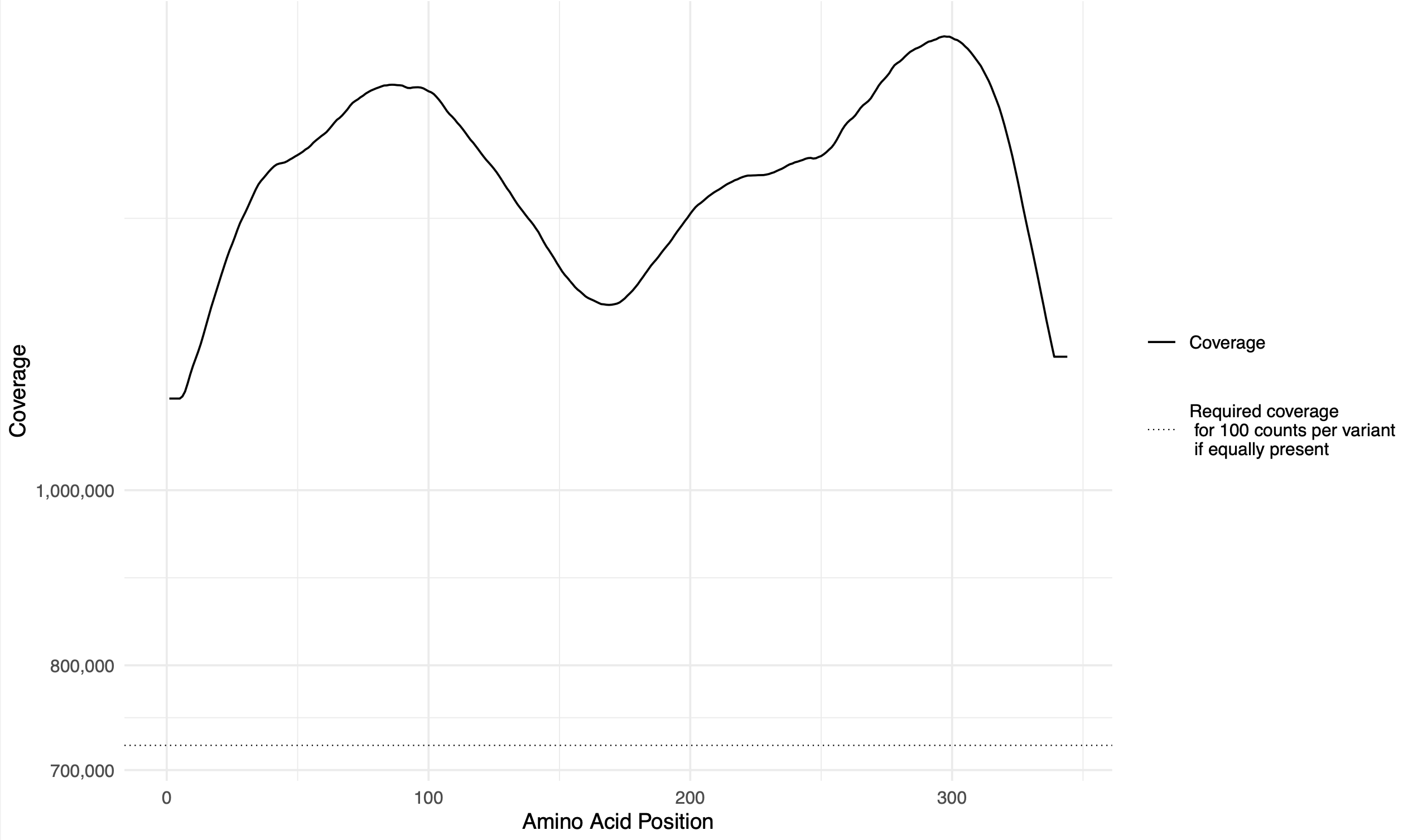
-
rolling_counts.pdf: sliding-window rolling coverage, stratified by hamming distance to the wildtype nucleotide sequence (colour shading)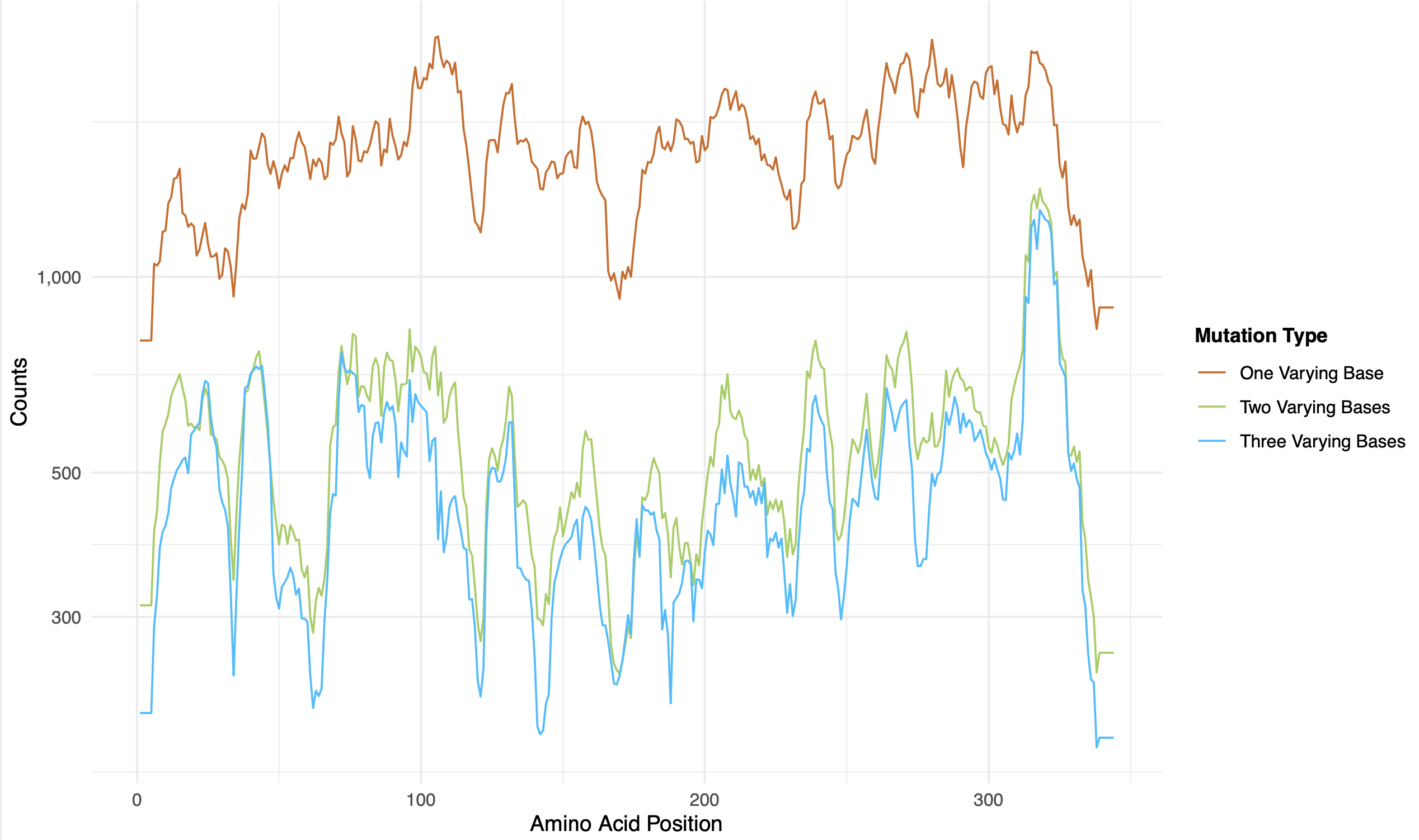
-
rolling_counts_per_cov.pdf: as above, but as a fraction of the total sequencing coverage -
SeqDepth.pdf(optional via the--run_seqdepthargument): rarefaction curve of the sequencing coverage and how it relates to the percentage of programmed variants detected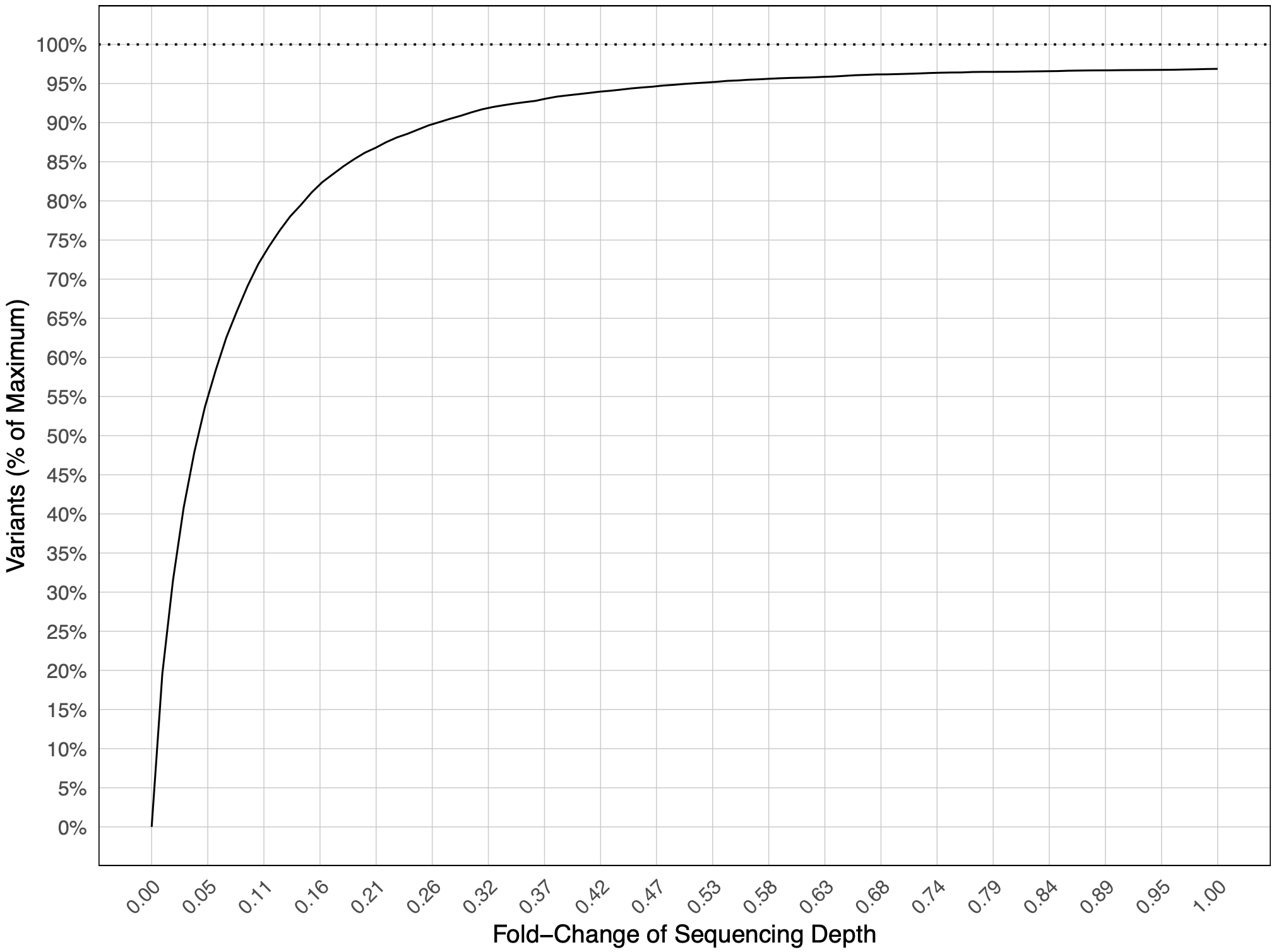
-
<sample>/<sample>_error_correction_report.html(unless--error_correction none): a self-contained interactive report showing the effect of the sequencing-error correction — positional error bias along the ORF, the distribution of per-variant correction magnitude, a raw-vs-corrected scatter, and a searchable per-variant table.
-
Fitness (Core Pipeline Stages 6-8)
This directory is created during the final series of steps of the pipeline, featuring fitness and fitness error estimates (when DMS input/output sample groups are specified).
Output files
-
fitness/-
counts_merged.tsv: summarised gene variant counts across all input and output samples -
default_results/fitness_estimation_count_correlation.pdf: pair-wise replicate variant count scatterplots and correlations between all specified samples
-
default_results/fitness_estimation_fitness_correlation.pdf: pair-wise fitness replicate scatterplots and correlations between all specified output samples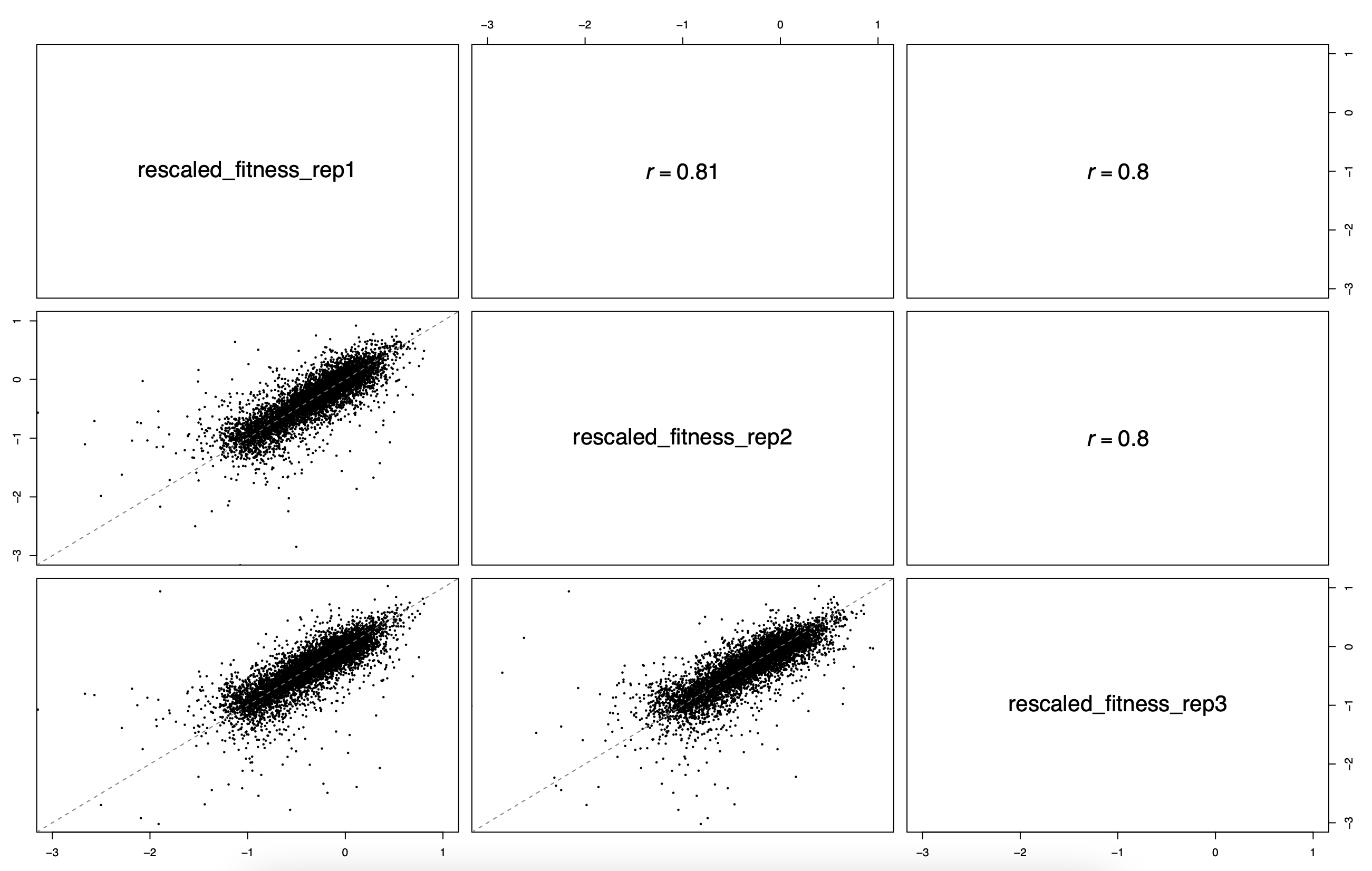
-
default_results/fitness_heatmap.pdf: a complete heatmap of absolute mutant counts, stratified by mutant amino acid (Y-axis) per position (X-axis)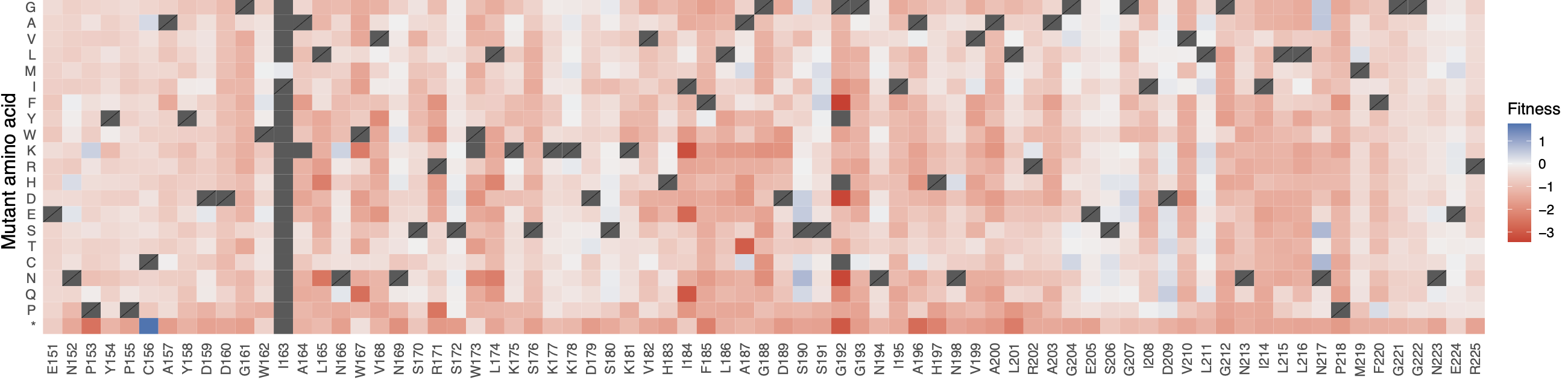
-
default_results/fitness_estimation.tsv: table file with all fitness and fitness error estimates calculated -
DiMSum_results/dimsum_results/(optional): subfolder with the full set of DiMSum outputs, including the associated.HTMLreport,.Rdataand.tsvfiles with fitness and fitness error estimates
-
-
<sample>/variant_effect_inspection_tool.html(only with--pdb): a single, portable, interactive HTML tool that projects per-residue metrics (fitness, coverage, counts, counts/coverage, and — when correction is on — positional error bias) onto the supplied wildtype 3D structure. Select a residue to inspect each substitution’s effect; download high-resolution images/PyMOL sessions. Works offline and can be shared as a single file.
Pipeline Info (Nextflow Reports)
pipeline_info/- Reports generated by Nextflow:
execution_report.html,execution_timeline.html,execution_trace.txtandpipeline_dag.dot/pipeline_dag.svg. - Reports generated by the pipeline:
pipeline_report.html,pipeline_report.txtandsoftware_versions.yml. Thepipeline_report*files will only be present if the--email/--email_on_failparameter’s are used when running the pipeline. - Reformatted samplesheet files used as input to the pipeline:
samplesheet.valid.csv. - Parameters used by the pipeline run:
params.json.
- Reports generated by Nextflow:
Nextflow provides excellent functionality for generating various reports relevant to the running and execution of the pipeline. This will allow you to troubleshoot errors with the running of the pipeline, and also provide you with other information such as launch commands, run times and resource usage.