Introduction
nf-core/oncoanalyser is a Nextflow implementation of the comprehensive cancer DNA/RNA analysis and reporting workflow from the Hartwig Medical Foundation (HMF). The workflow starts from FASTQ or BAM and calls genomic variants, analyses transcript data, infers important biomarkers and features (e.g. TMB, HRD, mutational signatures, HLA alleles, oncoviral content, tissue of origin, etc), annotates and interprets results in the clinical context, and more.
Both the HMF WGS/WTS workflow and targeted sequencing workflow are available in oncoanalyser. The targeted sequencing workflow has built-in support for the TSO500 panel and can also run custom panels with externally-generated normalisation data.
The key analysis results for each sample are summarised and presented in an ORANGE report (summary page excerpt shown below from COLO829_wgts.orange_report.pdf):
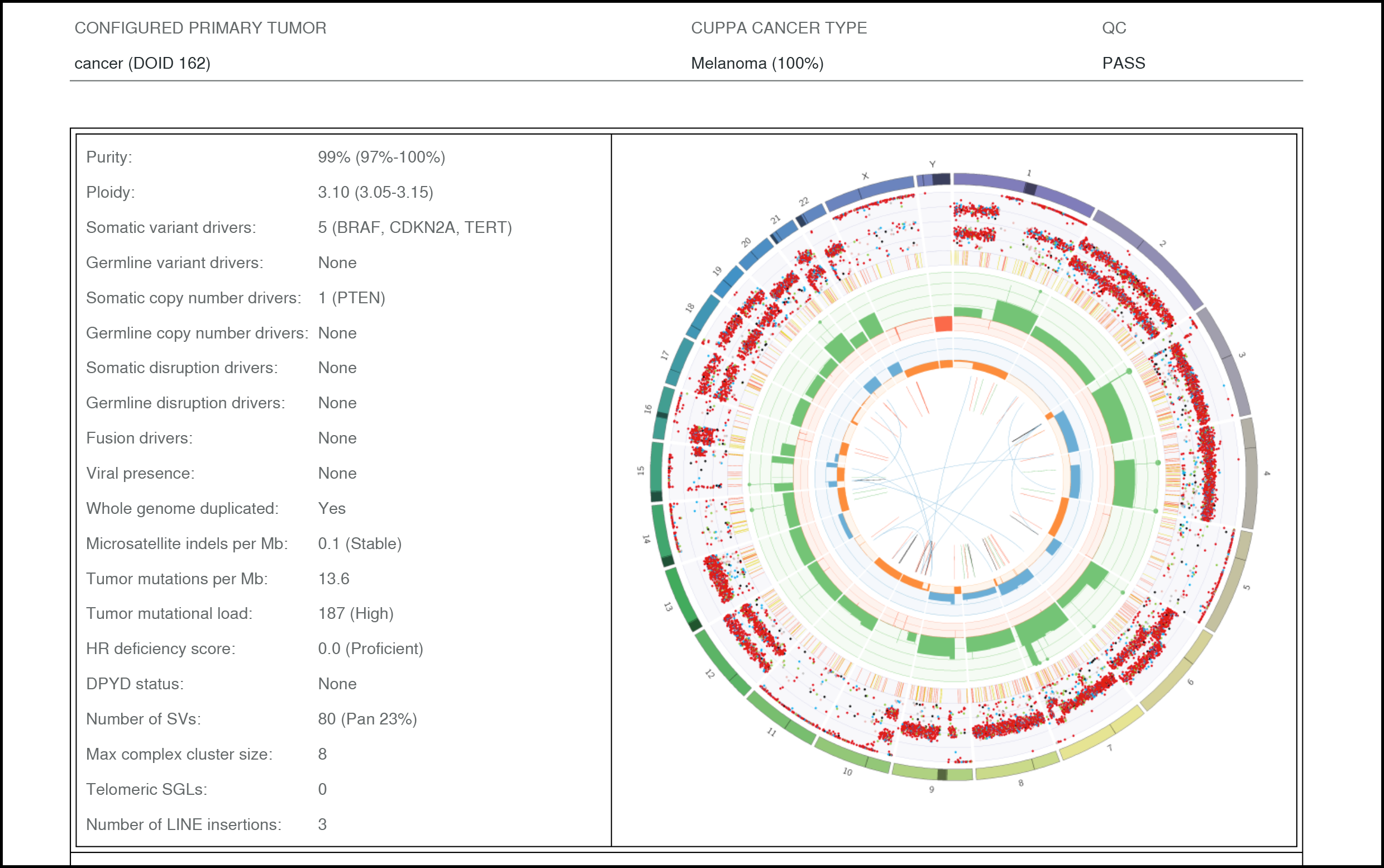
For detailed information on each component of the HMF workflow, please refer to hartwigmedical/hmftools.
Pipeline summary
The following processes and tools can be run with oncoanalyser:
- Simple DNA/RNA alignment (
bwa-mem2,STAR) - Post-alignment processing (
MarkDups,Picard MarkDuplicates) - SNV, MNV, and INDEL calling (
SAGE,PAVE) - CNV calling (
AMBER,COBALT,PURPLE) - SV calling (
SvPrep,GRIDSS,GRIPSS) - SV event interpretation (
LINX) - Transcript analysis (
Isofox) - Oncoviral detection (
VIRUSBreakend,Virus Interpreter) - HLA calling (
LILAC) - HRD status prediction (
CHORD) - Mutational signature fitting (
Sigs) - Tissue of origin prediction (
CUPPA) - Report generation (
ORANGE,linxreport)
Usage
If you are new to Nextflow and nf-core, please refer to this page on how to set-up Nextflow. Make sure to test your setup with -profile test before running the workflow on actual data.
Create a samplesheet with your inputs (WGS/WTS FASTQs in this example):
group_id,subject_id,sample_id,sample_type,sequence_type,filetype,info,filepath
P1__wgts,P1,SA,normal,dna,fastq,library_id:SA_library;lane:001,/path/to/SA.normal.dna.wgs.001.R1.fastq.gz;/path/to/SA.normal.dna.wgs.001.R2.fastq.gz
P1__wgts,P1,SB,tumor,dna,fastq,library_id:SB_library;lane:001,/path/to/SB.tumor.dna.wgs.001.R1.fastq.gz;/path/to/SB.tumor.dna.wgs.001.R2.fastq.gz
P1__wgts,P1,SC,tumor,rna,fastq,library_id:SC_library;lane:001,/path/to/SC.tumor.rna.wts.001.R1.fastq.gz;/path/to/SC.tumor.rna.wts.001.R2.fastq.gzLaunch oncoanalyser:
nextflow run nf-core/oncoanalyser \
-profile docker \
-revision 1.0.0 \
--mode wgts \
--genome GRCh38_hmf \
--input samplesheet.csv \
--outdir output/Please provide pipeline parameters via the CLI or Nextflow -params-file option. Custom config files including those provided by the -c Nextflow option can be used to provide any configuration except for parameters; see docs.
For more details and further functionality, please refer to the usage documentation and the parameter documentation.
Pipeline output
To see the results of an example test run with a full size dataset refer to the results tab on the nf-core website pipeline page. For more details about the output files and reports, please refer to the output documentation.
Version information
Extended support
As oncoanalyser is used in clinical settings and subject to accreditation standards in some instances, there is a need
for long-term stability and reliability for feature releases in order to meet operational requirements. This is
accomplished through long-term support of several nominated feature releases, which all receive bug fixes and security
fixes during the period of extended support.
Each release that is given extended support is allocated a separate long-lived git branch with the ‘stable’ prefix, e.g.
stable/1.2.x, stable/1.5.x. Feature development otherwise occurs on the dev branch with stable releases pushed to
master.
Versions nominated to have current long-term support:
- TBD
Release parity
Versioning between oncoanalyser and hmftools naturally differ, however it is often necessary to relate the functional
equivalence of these two pieces of software. The functional/feature parity with regards to version releases are detailed
in the below table.
| oncoanalyser | hmftools |
|---|---|
| 0.1.0 through 0.2.7 | 5.33 |
| 0.3.0 through 1.0.0 | 5.34 |
Known issues
There are currently no known issues.
Credits
The oncoanalyser pipeline was written by Stephen Watts while in the Genomics Platform
Group at the University
of Melbourne Centre for Cancer Research.
We thank the following organisations and people for their extensive assistance in the development of this pipeline, listed in alphabetical order:
- Hartwig Medical Foundation Australia
- Oliver Hofmann
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don’t hesitate to get in touch on the Slack #oncoanalyser
channel (you can join with this invite).
Citations
You can cite the oncoanalyser zenodo record for a specific version using the following doi:
10.5281/zenodo.XXXXXXX
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md
file.
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.
run with
subscribers
stars
open issues
open PRs
last release
last update
contributors
")
")
")