nf-core/quantms
Quantitative mass spectrometry workflow. Currently supports proteomics experiments with complex experimental designs for DDA-LFQ, DDA-Isobaric and DIA-LFQ quantification.
1.0). The latest stable release is1.2.0.Introduction
This document describes the output produced by the pipeline. Most of the plots are taken from the MultiQC report, which summarises results at the end of the pipeline.
The directories listed below will be created in the results directory after the pipeline has finished. All paths are relative to the top-level results directory.
Pipeline overview
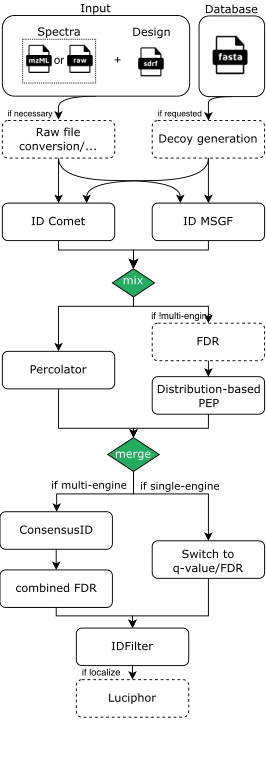
The pipeline is built using Nextflow and processes data using the following steps for DDA-LFQ and DDA-ISO data:
- (optional) Conversion of spectra data to indexedMzML: Using ThermoRawFileParser if Thermo Raw or using OpenMS’ FileConverter if just an index is missing
- (optional) Decoy database generation for the provided DB (fasta) with OpenMS
- Database search with either MSGF+ and/or Comet through OpenMS adapters
- Re-mapping potentially identified peptides to the input database for consistency and error-checking (using OpenMS’ PeptideIndexer)
- PSM rescoring using PSMFeatureExtractor and Percolator or a PeptideProphet-like distribution fitting approach in OpenMS
- If multiple search engines were chosen, the results are combined with OpenMS’ ConsensusID
- If multiple search engines were chosen, a combined FDR is calculated
- Single run PSM/Peptide-level FDR filtering
- If localization of modifications was requested, Luciphor2 is applied via the OpenMS adapter
- (DDA-LFQ) Protein inference and label-free quantification based on spectral counting or MS1 feature detection, alignment and integration with OpenMS’ ProteomicsLFQ. Performs an additional experiment-wide FDR filter on protein (and if requested peptide/PSM-level).
- (DDA-ISO) Extracts and normalizes isobaric labeling
- (DDA-ISO) Protein inference using the OpenMS ProteinInference tool. In addition, protein FDR filtering is performed in this step for Isobaric datasets (TMT, iTRAQ).
- (DDA-ISO) Protein Quantification
- Generation of QC reports using pMultiQC a library for QC proteomics data analysis.
For DIA-LFQ experiments, the workflows is different:
- RAW data is converted to mzML using the ThermoRawFileParser
- DIA-NN is used to for identification, quantification of the peptides and proteins
- Generation of output files
- Generation of QC reports using pMultiQC a library for QC proteomics data analysis.
As an example, a rough visualization of the DDA identification subworkflow can be seen here:
Output structure
Output is by default written to the $NXF_WORKSPACE/results folder. Each step of the workflow export different files and reports with the specific data, peptide identifications, protein quantifications, etc. Most of the pipeline outputs are HUPO-PSI standard file formats:
- mzML: The mzML format is an open, XML-based format for mass spectrometer output files, developed with the full participation of vendors and researchers in order to create a single open format that would be supported by all software.
- mzTab: mzTab is intended as a lightweight supplement to the existing standard mzML to store and represent peptide and protein and identifications together with experimental metadata and basic quantitative information.
The output consists of the following folders (follow the links for a more detailed description):
results
- spectra data:
- identification results:
- consensusID identifications:
- pipeline information:
- DDA-LFQ quantification results:
- DDA-ISO quantification results:
- DIA-LFQ quantification results:
- MSstats-processed results
Output description
Nextflow pipeline info
Nextflow provides excellent functionality for generating various reports relevant to the running and execution of the pipeline. This will allow you to troubleshoot errors with the running of the pipeline, and also provide you with other information such as launch commands, run times and resource usage.
Output files
-pipeline_info/ - Reports generated by Nextflow: execution_report.html, execution_timeline.html, execution_trace.txt and pipeline_dag.dot/pipeline_dag.svg. - Reports generated by the pipeline: pipeline_report.html, pipeline_report.txt and software_versions.yml. The pipeline_report* files will only be present if the --email / --email_on_fail parameter’s are used when running the pipeline. - Reformatted samplesheet files used as input to the pipeline: samplesheet.valid.csv.
File types
Spectra
Quantms main format for spectra is the open mzML format. However it also supports Thermo raw files through conversion with ThermoRawFileParser. Mixed inputs should be possible but are untested. Conversion results can be cached if run locally or outputted to results. Mismatches between file extensions in the design and on disk can be corrected through parameters.
Protein database
The input protein database needs to be in standard fasta format. We recommend removing stop codons * in a way that is suitable to your analysis to avoid
different handling between peptide search engines.
Identifications
Intermediate output for the PSM/peptide-level filtered identifications per raw/mzML file happens in OpenMS’ internal idXML format. Only for DDA currently.
Quantities
Depending on the mode, quantms reports its outputs for quantities in different folders and formats, see Output structure.
ConsensusXML
A consensusXML file as the closest representation of the internal data structures generated by OpenMS. Helpful for debugging and downstream processing with OpenMS tools.
Tab-based OpenMS formats
In addition to the consensusXML and idXML formats, OpenMS generates other formats that can help the downstream analysis of the quantms results. DDA-LFQ only.
- peptide_out.tsv: The peptide output (peptide_out.tsv) from ProteinQuantifier contains a peptide table with the corresponding quantification data.
- protein_out.tsv: The protein output (protein_out.tsv) from ProteinQuantifier contains the protein information including quantification values.
MSstats-ready quantity tables
MSstats output is generated for all three pipelines DDA-LFQ, DDA-ISO and DIA-LFQ. A simple tsv file ready to be read by the OpenMStoMSstats function of the MSstats R package. It should hold the same quantities as the consensusXML but rearranged in a “long” table format with additional information about the experimental design used by MSstats.
Triqler
Output to be used as input in Triqler has similar information in a tsv format as the output for MSstats. Additionally, it contains quantities for decoy identifications and search engine scores.
mzTab
The mzTab is exported for all three workflows DDA-LFQ, DDA-ISO and DIA-LFQ. It is a complete mzTab file ready for submission to PRIDE. It contains both identifications (only those responsible for a quantification), quantities as well as some metadata about both the experiment and the quantification.
MSstats-processed mzTab
If MSstats was enabled, the pipeline additionally exports an mzTab file where the quantities are replaced with the normalized and imputed ones from MSstats.
MultiQC and pMultiQC
Output files
multiqc/<ALIGNER>/multiqc_report.html: a standalone HTML file that can be viewed in your web browser.multiqc_data/: directory containing parsed statistics from the different tools used in the pipeline.
All the QC results for proteomics are currently generated by the pMultiQC library, a plugin of the popular visualization tool MultiQC. MultiQC is a visualization tool that generates a single HTML report summarising all samples in your project. Most of the pipeline QC results are visualised in the report and further statistics are available in the report data directory.
Results generated by pMultiQC collate pipeline QC from identifications and quantities over the course of the pipeline. The pipeline has special steps which also allow the software versions to be reported in the MultiQC output for future traceability. For more information about how to use pMultiQC reports in general, see https://github.com/bigbio/pmultiqc.