Introduction
nf-core/airrflow allows processing B-cell receptor (BCR) and and T-cell receptor (TCR) sequencing data from bulk and single-cell sequencing protocols. It allows the processing of targeted bulk and single-cell adaptive immune receptor sequencing data (AIRR-seq), as well as the extraction of TCR and BCR sequences from untargeted bulk and single-cell RNA-seq data. The pipeline enables and end-to-end analysis, departing from raw reads or readily assembled sequences, and performs sequence assembly, V(D)J assignment, clonal group inference, lineage reconstruction and repertoire analysis using the Immcantation framework, as well as other immune repertoire analysis tools.
In addition to this page, you can find additional information on how to use the pipeline on the following pages:
- bulk_tutorial: a step by step tutorial on how to run nf-core/airrflow for bulk data.
- single_cell_tutorial: a step by step tutorial on how to run nf-core/airrflow for single-cell data.
- genotyping_tutorial: a tutorial on how to perform novel allele detection and genotype inference with nf-core/airrflow.
Running the pipeline
Quickstart
[!INSTALLATION] If you are new to Nextflow and nf-core, please refer to this page on how to set up Nextflow and a container engine needed to run this pipeline. At the moment, nf-core/airrflow does NOT support using conda virtual environments for dependency management, only containers are supported. Make sure to test your setup with
-profile testbefore running the workflow on actual data.
First, ensure that the pipeline tests run on your infrastructure:
nextflow run nf-core/airrflow -profile test,<docker/singularity/apptainer/podman/shifter/charliecloud/conda/institute> --outdir <OUTDIR>A typical command for running the pipeline for bulk raw fastq files using available pre-set protocol profiles is shown below. The full list of supported profiles can be found in the section Supported protocol profiles.
nextflow run nf-core/airrflow \-profile nebnext_umi_bcr,docker \--input input_samplesheet.tsv \--outdir resultsIt is also possible to process custom sequencing protocols with custom primers by manually specifying the primers, UMI length (if available) and position:
nextflow run nf-core/airrflow \-profile <docker/singularity/podman/shifter/charliecloud/conda/institute> \--mode fastq \--input input_samplesheet.tsv \--library_generation_method specific_pcr_umi \--cprimers CPrimers.fasta \--vprimers VPrimers.fasta \--umi_length 12 \--umi_position R1 \--outdir resultsA typical command to run the pipeline from single cell raw fastq files is:
nextflow run nf-core/airrflow \-profile <docker/singularity/podman/shifter/charliecloud/conda/institute> \--mode fastq \--input input_samplesheet.tsv \--library_generation_method sc_10x_genomics \--reference_10x reference/refdata-cellranger-vdj-GRCh38-alts-ensembl-5.0.0.tar.gz \--outdir resultsA typical command for running the pipeline departing from single-cell AIRR rearrangement tables or assembled bulk sequencing fasta data is:
nextflow run nf-core/airrflow \-profile <docker/singularity/podman/shifter/charliecloud/conda/institute> \--input input_samplesheet.tsv \--mode assembled \--outdir resultsIt is also possible to reconstruct BCR and TCR sequences from untargeted bulk and single-cell sequencing data. A typical command to run the pipeline from single-cell RNA-seq fastq files is shown below. For more information, check the section on supported untargeted RNA-seq based methods below.
nextflow run nf-core/airrflow \-profile <docker/singularity/podman/shifter/charliecloud/conda/institute> \--mode fastq \--input input_samplesheet.tsv \--library_generation_method trust4 \--umi_read R1 \--cell_barcode_read R1 \--read_format bc:0:15,um:16:27 \--outdir resultsIf you want to detect novel alleles and infer genotype of each individual, add the --genotyping flag in your command. Novel alleles detection and genotype inference currently work only for BCR sequences.
Check the section Input samplesheet below for instructions on how to create the samplesheet, and the Supported library generation protocols section below for examples on how to run the pipeline for the different bulk and single-cell sequencing protocols.
For more detailed information about all the available parameters, please refer to the parameters documentation.
The command above will launch the pipeline with the docker configuration profile. See below for more information about profiles.
Note that the pipeline will create the following files in your working directory:
work # Directory containing the nextflow working files<OUTDIR> # Finished results (configurable, see below).nextflow_log # Log file from Nextflow# Other nextflow hidden files, eg. history of pipeline runs and old logs.If you wish to repeatedly use the same parameters for multiple runs, rather than specifying each flag in the command, you can specify these in a params file.
Pipeline settings can be provided in a yaml or json file via -params-file <file>.
Do not use -c <file> to specify parameters as this will result in errors. Custom config files specified with -c must only be used for tuning process resource specifications, other infrastructural tweaks (such as output directories), or module arguments (args).
The above pipeline run specified with a params file in yaml format:
nextflow run nf-core/airrflow -profile docker -params-file params.yamlwith:
input: './samplesheet.csv'outdir: './results/'<...>You can also generate such YAML/JSON files via nf-core/launch.
Updating the pipeline
When you run the above command, Nextflow automatically pulls the pipeline code from GitHub and stores it as a cached version. When running the pipeline after this, it will always use the cached version if available - even if the pipeline has been updated since. To make sure that you’re running the latest version of the pipeline, make sure that you regularly update the cached version of the pipeline:
nextflow pull nf-core/airrflowReproducibility
It is a good idea to specify the pipeline version when running the pipeline on your data. This ensures that a specific version of the pipeline code and software are used when you run your pipeline. If you keep using the same tag, you’ll be running the same version of the pipeline, even if there have been changes to the code since.
First, go to the nf-core/airrflow releases page and find the latest pipeline version - numeric only (eg. 1.3.1). Then specify this when running the pipeline with -r (one hyphen) - eg. -r 1.3.1. Of course, you can switch to another version by changing the number after the -r flag.
This version number will be logged in reports when you run the pipeline, so that you’ll know what you used when you look back in the future. For example, at the bottom of the MultiQC reports.
To further assist in reproducibility, you can use share and reuse parameter files to repeat pipeline runs with the same settings without having to write out a command with every single parameter.
If you wish to share such profile (such as upload as supplementary material for academic publications), make sure to NOT include cluster specific paths to files, nor institutional specific profiles.
Input samplesheet
Fastq input samplesheet (bulk AIRR sequencing)
The required input file for processing raw BCR or TCR bulk targeted sequencing data is a sample sheet in TSV format (tab separated). The columns sample_id, filename_R1, filename_R2, subject_id, species, tissue, pcr_target_locus, single_cell, sex, age and biomaterial_provider are required. An example samplesheet is:
| sample_id | filename_R1 | filename_R2 | filename_I1 | subject_id | species | pcr_target_locus | tissue | sex | age | biomaterial_provider | single_cell | intervention | collection_time_point_relative | cell_subset |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sample01 | sample1_S8_L001_R1_001.fastq.gz | sample1_S8_L001_R2_001.fastq.gz | sample1_S8_L001_I1_001.fastq.gz | Subject02 | human | IG | blood | NA | 53 | sequencing_facility | FALSE | Drug_treatment | Baseline | plasmablasts |
| sample02 | sample2_S8_L001_R1_001.fastq.gz | sample2_S8_L001_R2_001.fastq.gz | sample2_S8_L001_I1_001.fastq.gz | Subject02 | human | TR | blood | female | 78 | sequencing_facility | FALSE | Drug_treatment | Baseline | plasmablasts |
sample_id: Sample ID assigned by submitter, unique within study.filename_R1: path to fastq file with first mates of paired-end sequencing.filename_R2: path to fastq file with second mates of paired-end sequencing.filename_I1(optional): path to fastq with illumina index and UMI (unique molecular identifier) barcode.subject_id: Subject ID assigned by submitter, unique within study.species: species from which the sample was taken. Supported species arehumanandmouse.tissue: tissue from which the sample was taken. E.g.blood,PBMC,brain.pcr_target_locus: Designation of the target locus (IGorTR).biomaterial_provider: Institution / research group that provided the samples.sex: Subject biological sex (female,male, etc.).age: Subject biological age.single_cell: TRUE or FALSE.
Other optional columns can be added. These columns will be available as metadata in the final repertoire table. It is recommended that these columns also follow the AIRR nomenclature. Examples are:
intervention: Description of intervention.disease_diagnosis: Diagnosis of subject.collection_time_point_relative: Time point at which sample was taken, relative tocollection_time_point_reference(e.g. 14d, 6 months, baseline).collection_time_point_reference: Event in the study schedule to whichSample collection timerelates to (e.g. primary vaccination, intervention start).cell_subset: Commonly-used designation of isolated cell population.
It is possible to provide several fastq files per sample (e.g. sequenced over different chips or lanes). In this case the different fastq files per sample will be merged together prior to processing. Provide one fastq pair R1/R2 per row, and the same sample_id field for these rows.
Fastq input samplesheet (single-cell AIRR sequencing)
The required input file for processing raw BCR or TCR single cell targeted sequencing data is a sample sheet in TSV format (tab separated). The columns sample_id, filename_R1, filename_R2, subject_id, species, tissue, pcr_target_locus, single_cell, sex, age and biomaterial_provider are required. Any other columns you add will be available in the final repertoire file as extra metadata fields. You can refer to the bulk fastq input section for documentation on the individual columns.
An example samplesheet is:
| sample_id | filename_R1 | filename_R2 | subject_id | species | pcr_target_locus | tissue | sex | age | biomaterial_provider | single_cell |
|---|---|---|---|---|---|---|---|---|---|---|
| sample01 | sample01_S1_L001_R1_001.fastq.gz | sample01_S1_L001_R2_001.fastq.gz | Subject02 | human | IG | blood | NA | 53 | sequencing_facility | TRUE |
| sample02 | sample02_S1_L001_R1_001.fastq.gz | sample02_S1_L001_R2_001.fastq.gz | Subject02 | human | TR | blood | female | 78 | sequencing_facility | TRUE |
FASTQ files must conform with the 10xGenomics cellranger naming conventions with the same sample name as provided in the sampleid column
>**[SAMPLE-NAME]S[CHIP-NUMBER]_ L00[LANE-NUMBER]_[R1/R2]_001.fastq.gz**Read type is one of
I1: Sample index read (optional)I2: Sample index read (optional)R1: Read 1R2: Read 2
It is possible to provide several fastq files per sample (e.g. sequenced over different chips or lanes). In this case the different fastq files per sample will be provided to the same cellranger process. These rows should then have an identical sample_id field.
Fastq input samplesheet (untargeted bulk or single-cell RNA-seq)
When running the untargeted protocol, BCR or TCR sequences will be extracted from the untargeted bulk or single-cell RNA sequencing with tools such as TRUST4. The required input file is the same as for the Fastq bulk AIRR samplesheet or Fastq single-cell AIRR samplesheet depending on the input data type (bulk RNA-seq or single-cell RNA-seq).
Assembled input samplesheet (bulk or single-cell sequencing)
The required input file for processing raw BCR or TCR bulk targeted sequencing data is a sample sheet in TSV format (tab separated). The columns sample_id, filename, subject_id, species, tissue, single_cell, sex, age and biomaterial_provider are required. All fields are explained in the previous section, with the only difference being that there is only one filename column for the assembled input samplesheet. The provided file will be different from assembled single-cell or bulk data:
filenamefor single-cell assembled data: path toairr_rearrangement.tsvfile, for example the one generated when processing the 10x Genomics scBCRseq / scTCRseq with 10x Genomics cellrangercellranger vdjorcellranger multi. The field accepts any tsv tables following the AIRR rearrangement Schema specification. See here for more details on the cellranger output.filenamefor bulk assembled data: path tosequences.fastafile, containing the assembled and error-corrected reads.
The required input file for processing raw BCR or TCR bulk targeted sequencing data is a sample sheet in TSV format (tab separated). The columns sample_id, filename, subject_id, species, tissue, single_cell, pcr_target_locus, sex, age and biomaterial_provider are required.
An example samplesheet is:
| filename | species | subject_id | sample_id | tissue | sex | age | biomaterial_provider | pcr_target_locus | single_cell |
|---|---|---|---|---|---|---|---|---|---|
| sc5p_v2_hs_PBMC_1k_b_airr_rearrangement.tsv | human | subject_x | sc5p_v2_hs_PBMC_1k_5fb | PBMC | NA | NA | 10x Genomics | IG | TRUE |
| bulk-Laserson-2014.fasta | human | PGP1 | PGP1 | PBMC | male | NA | Laserson-2014 | IG | FALSE |
Supported AIRR metadata fields
nf-core/airrflow offers full support for the AIRR standards 1.4 metadata annotation. The minimum metadata fields that are needed by the pipeline are listed in the table below. Other non-mandatory AIRR fields can be provided in the input samplesheet, which will be available for reporting and introducing comparisons among repertoires.
| AIRR field | Type | Parameter Name | Description |
|---|---|---|---|
| sample_id | Samplesheet column | Sample ID assigned by submitter, unique within study | |
| subject_id | Samplesheet column | Subject ID assigned by submitter, unique within study | |
| species | Samplesheet column | Subject species | |
| tissue | Samplesheet column | Sample tissue | |
| pcr_target_locus | Samplesheet column | Designation of the target locus (IG or TR) | |
| sex | Samplesheet column | Subject sex | |
| age | Samplesheet column | Subject age | |
| biomaterial_provider | Samplesheet column | Name of sample biomaterial provider | |
| library_generation_method | Parameter | --library_generation_method |
Generic type of library generation |
Supported protocol profiles
NEBNext Immune Sequencing Kit
You can use the nebnext_umi_bcr or nebnext_umi_tcr preset defaults for analyzing bulk fastq sequencing data that was generated with the NEB Immune Profiling kit. An example using docker containers for the analysis is:
nextflow run nf-core/airrflow -r <release> \-profile nebnext_umi_bcr,docker \--input input_samplesheet.tsv \--outdir resultsThis profile executes the commands based on the pRESTO pre-set pipeline presto-abseq.sh. A summary of the performed steps is:
- Filter sequences by base quality.
- Score and mask the provided R1 primers and R2 template switch oligo. Primer defaults are taken from the Immcantation repository.
- Pair sequences, build UMI consensus sequence.
- Assemble read pairs with the pRESTO
AssemblePairs sequentialoption. - Align and annotate the internal C Region (for the BCR specific protocol) for a more specific isotype annotation.
- Remove duplicate sequences and filter to sequences with at least 2 supporting sources.
Please note that the default primer sequences and internal CRegion sequences are for human. If you wish to run this protocol on mouse or other species, please provide the alternative primers. Here is an example using the mouse IG primers from the Immcantation GitHub repository:
nextflow run nf-core/airrflow -r <release> \-profile nebnext_umi_bcr,docker \--input input_samplesheet.tsv \--cprimers https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/AbSeq/AbSeq_R1_Mouse_IG_Primers.fasta \--internal_cregion_sequences https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/AbSeq/AbSeq_Mouse_IG_InternalCRegion.fasta \--outdir resultsAnd similarly for TCR libraries:
nextflow run nf-core/airrflow -r <release> \-profile nebnext_umi_tcr,docker \--input input_samplesheet.tsv \--cprimers https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/AbSeq/AbSeq_R1_Mouse_TR_Primers.fasta \--internal_cregion_sequences https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/AbSeq/AbSeq_Mouse_TR_InternalCRegion.fasta \--outdir resultsTakara SMART-Seq Human BCR/TCR Profiling kit
This protocol was previously called clontech_umi_bcr/clontech_umi_tcr and we’ve updated it to TAKARA SMART-Seq to reflect the current name of the experimental kit.
You can use the takara_smartseq_umi_bcr or takara_smartseq_umi_tcr preset defaults for analyzing bulk fastq sequencing data that was generated with the Takara SMARTer Human Profiling kit. An example using docker containers for the analysis is:
nextflow run nf-core/airrflow -r <release> \-profile takara_smartseq_umi_bcr,docker \--input input_samplesheet.tsv \--outdir resultsThis profile executes the sequence assembly commands based on the pRESTO pre-set pipeline presto-clontech-umi.sh. A summary of the performed steps is:
- Filter sequences by base quality.
- Align and annotate the universal C region sequences in the R1 reads. Defaults are taken from the Immcantation repository.
- Identify the primers sequences and UMI (12 nt length) in the R2 reads.
- Pair sequences, build UMI consensus sequence.
- Assemble read pairs with the pRESTO
AssemblePairs sequentialoption. - Align and annotate the C Region sequences.
- Remove duplicate sequences and filter to sequences with at least 2 supporting sources.
After the sequence assembly steps, the remaining steps are common for all protocols.
Please note that the default primer sequences and internal CRegion sequences are for human. If you wish to run this protocol on mouse or other species, please provide the alternative primer sequences. Here is an example using the mouse IG primers from the Immcantation GitHub repository:
nextflow run nf-core/airrflow -r <release> \-profile takara_smartseq_umi_bcr,docker \--input input_samplesheet.tsv \--cprimers https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/Universal/Mouse_IG_CRegion_RC.fasta \--outdir resultsAnd for TCR data:
nextflow run nf-core/airrflow -r <release> \-profile takara_smartseq_umi_tcr,docker \--input input_samplesheet.tsv \--cprimers https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/Universal/Mouse_TR_CRegion_RC.fasta \--outdir resultsTakara SMARTer Human BCR/TCR Profiling kit
You can use the takara_smarter_umi_bcr or takara_smarter_umi_tcr preset defaults for analyzing bulk fastq sequencing data that was generated with the Takara SMARTer Human Profiling kit. An example using docker containers for the analysis is:
nextflow run nf-core/airrflow -r <release> \-profile takara_smarter_umi_bcr,docker \--input input_samplesheet.tsv \--outdir resultsThis profile executes the sequence assembly commands based on the pRESTO pre-set pipeline presto-clontech-umi.sh. A summary of the performed steps is:
- Filter sequences by base quality.
- Align and annotate the universal C region sequences in the R1 reads. Defaults are taken from the Immcantation repository.
- Identify the primers sequences and UMI (12 nt length) in the R2 reads.
- Pair sequences, build UMI consensus sequence.
- Assemble read pairs with the pRESTO
AssemblePairs sequentialoption. - Align and annotate the C Region sequences.
- Remove duplicate sequences and filter to sequences with at least 2 supporting sources.
After the sequence assembly steps, the remaining steps are common for all protocols.
Please note that the default primer sequences and internal CRegion sequences are for human. If you wish to run this protocol on mouse or other species, please provide the alternative primer sequences. Here is an example using the mouse IG primers from the Immcantation GitHub repository:
nextflow run nf-core/airrflow -r <release> \-profile takara_smarter_umi_bcr,docker \--input input_samplesheet.tsv \--cprimers https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/Universal/Mouse_IG_CRegion_RC.fasta \--outdir resultsAnd for TCR data:
nextflow run nf-core/airrflow -r <release> \-profile takara_smarter_umi_tcr,docker \--input input_samplesheet.tsv \--cprimers https://raw.githubusercontent.com/immcantation/immcantation/refs/heads/master/protocols/Universal/Mouse_TR_CRegion_RC.fasta \--outdir resultsSupported custom bulk library generation methods (protocols)
For common sequencing protocols such as commercial kits please check the section above if your kit has a preset profile first, as this will greatly simplify running the pipeline. When processing bulk sequencing data departing from raw fastq reads, several sequencing protocols are supported which can be provided with the parameter --library_generation_method.
The following table matches the library generation methods as described in the AIRR metadata annotation guidelines to the value that can be provided to the --library_generation_method parameter.
| Library generation methods (AIRR) | Description | Name in pipeline |
|---|---|---|
| RT(RHP)+PCR | RT-PCR using random hexamer primers | Not supported |
| RT(oligo-dT)+PCR | RT-PCR using oligo-dT primers | Not supported |
| RT(oligo-dT)+TS+PCR | 5’-RACE PCR (i.e. RT is followed by a template switch (TS) step) using oligo-dT primers | dt_5p_race |
| RT(oligo-dT)+TS(UMI)+PCR | 5’-RACE PCR using oligo-dT primers and template switch primers containing UMI | dt_5p_race_umi |
| RT(specific)+PCR | RT-PCR using transcript-specific primers | specific_pcr |
| RT(specific)+TS+PCR | 5’-RACE PCR using transcript- specific primers | Not supported |
| RT(specific)+TS(UMI)+PCR | 5’-RACE PCR using transcript- specific primers and template switch primers containing UMIs | Not supported |
| RT(specific+UMI)+PCR | RT-PCR using transcript-specific primers containing UMIs | specific_pcr_umi |
| RT(specific+UMI)+TS+PCR | 5’-RACE PCR using transcript- specific primers containing UMIs | Not supported |
| RT(specific)+TS | RT-based generation of dsDNA without subsequent PCR. This is used by RNA-seq kits. | Not supported |
Multiplex specific PCR (with or without UMI)
This sequencing type requires setting --library_generation_method specific_pcr_umi if UMI barcodes were used, or --library_generation_method specific_pcr if no UMI barcodes were used (sans-umi). If the option without UMI barcodes is selected, the UMI length will be set automatically to 0.
It is required to provide the sequences for the V-region primers as well as the C-region primers used in the specific PCR amplification. Some examples of UMI and barcode configurations are provided. Depending on the position of the C-region primer, V-region primers and UMI barcodes, there are several possibilities detailed in the following subsections.
R1 read contains C primer (and UMI barcode)
The --cprimer_position and --umi_position (if UMIs are used) parameters need to be set to R1 (this is the default).
If there are extra bases between the UMI barcode and C primer, specify the number of bases with the --cprimer_start parameter (default zero). Set --cprimer_position R1 (this is the default).
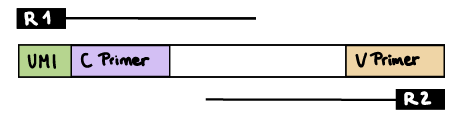
nextflow run nf-core/airrflow -profile docker \--input samplesheet.tsv \--library_generation_method specific_pcr_umi \--cprimers CPrimers.fasta \--vprimers VPrimers.fasta \--umi_length 12 \--umi_position R1 \--cprimer_start 0 \--cprimer_position R1 \--outdir ./resultsIf UMIs are not used:
nextflow run nf-core/airrflow -profile docker \--input samplesheet.tsv \--library_generation_method specific_pcr \--cprimers CPrimers.fasta \--vprimers VPrimers.fasta \--cprimer_start 0 \--cprimer_position R1 \--outdir ./resultsR1 read contains V primer (and UMI barcode)
The --umi_position parameter needs to be set to R1 (if UMIs are used), and --cprimer_position to R2.
If there are extra bases between the UMI barcode and V primer, specify the number of bases with the --vprimer_start parameter (default zero).
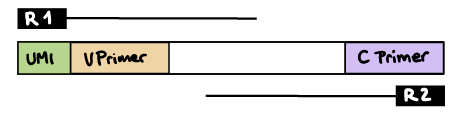
nextflow run nf-core/airrflow -profile docker \--input samplesheet.tsv \--library_generation_method specific_pcr_umi \--cprimers CPrimers.fasta \--vprimers VPrimers.fasta \--umi_length 12 \--umi_position R1 \--vprimer_start 0 \--cprimer_position R2 \--outdir ./resultsIf UMIs are not used:
nextflow run nf-core/airrflow -profile docker \--input samplesheet.tsv \--library_generation_method specific_pcr \--cprimers CPrimers.fasta \--vprimers VPrimers.fasta \--vprimer_start 0 \--cprimer_position R2 \--outdir resultsR2 read contains C primer (and UMI barcode)
The --umi_position and --cprimer_position parameters need to be set to R2.
If there are extra bases between the UMI barcode and C primer, specify the number of bases with the --cprimer_start parameter (default zero).
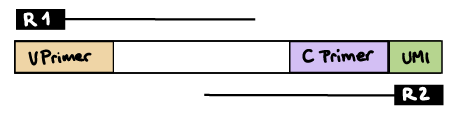
nextflow run nf-core/airrflow -profile docker \--input samplesheet.tsv \--library_generation_method specific_pcr_umi \--cprimers CPrimers.fasta \--vprimers VPrimers.fasta \--umi_length 12 \--umi_position R2 \--cprimer_start 0 \--cprimer_position R2 \--outdir ./resultsUMI barcode is provided in the index file
If the UMI barcodes are provided in an additional index file, please provide it in the column filename_I1 in the input samplesheet and additionally set the --index_file parameter. Specify the UMI barcode length with the --umi_length parameter. You can optionally specify the UMI start position in the index sequence with the --umi_start parameter (the default is 0).
For example:
nextflow run nf-core/airrflow -profile docker \--input samplesheet.tsv \--library_generation_method specific_pcr_umi \--cprimers Cprimers.fasta \--vprimers Vprimers.fasta \--cprimer_position R1 \--index_file \--umi_length 12 \--umi_start 6 \--outdir ./resultsUMI barcode handling
Unique Molecular Identifiers (UMIs) enable the quantification of BCR or TCR abundance in the original sample by allowing to distinguish PCR duplicates from original sample duplicates. The UMI indices are random nucleotide sequences of a pre-determined length that are added to the sequencing libraries before any PCR amplification steps, for example as part of the primer sequences.
The UMI barcodes are typically read from an index file but sometimes can be provided at the start of the R1 or R2 reads:
-
UMIs in the index file: if the UMI barcodes are provided in an additional index file, set the
--index_fileparameter. Specify the UMI barcode length with the--umi_lengthparameter. You can optionally specify the UMI start position in the index sequence with the--umi_startparameter (the default is 0). -
UMIs in R1 or R2 reads: if the UMIs are contained within the R1 or R2 reads, set the
--umi_positionparameter toR1orR2, respectively. Specify the UMI barcode length with the--umi_lengthparameter. -
No UMIs in R1 or R2 reads: if no UMIs are present in the samples, specify
--umi_length 0to use the sans-UMI subworkflow.
Supported single cell library generation methods (protocols)
When processing single cell sequencing data departing from raw fastq reads, currently only a --library_generation_method to support 10xGenomics data is available.
| Library generation methods | Description | Name in pipeline | Commercial protocols |
|---|---|---|---|
| RT(RHP)+PCR | sequencing data produced from Chromium single cell 5’V(D)J libraries containing cellular barcodes and UMIs. | sc_10x_genomics | 10xGenomics |
10xGenomics
This sequencing type requires setting --library_generation_method sc_10x_genomics.
The cellranger vdj tool automatically uses the Chromium cell barcodes and UMIs to perform sequence assembly, paired clonotype calling and to assemble V(D)J transcripts per cell. The pipeline will then perform gene reassignment and clonotyping with the Immcantation framework unless otherwise specified.
Examples are provided below to run airrflow to process 10xGenomics raw FASTQ data.
nextflow run nf-core/airrflow -r dev \-profile <docker/singularity/podman/shifter/charliecloud/conda/institute> \--mode fastq \--input input_samplesheet.tsv \--library_generation_method sc_10x_genomics \--reference_10x reference/refdata-cellranger-vdj-GRCh38-alts-ensembl-5.0.0.tar.gz \--outdir ./results10xGenomics reference
10xGenomics requires a reference. This can be provided using the --reference_10x parameter.
- The 10xGenomics reference can be downloaded from the download page
- To generate a V(D)J segment fasta file as reference from IMGT one can follow the cellranger docs.
Supported untargeted RNA-seq based methods
nf-core/airrflow supports untargeted bulk or single-cell RNA-seq fastq files as input. TRUST4 is used to extract TCR/BCR sequences from these files. The resulting AIRR tables are then fed into airrflow’s Immcantation based workflow.
To use untargeted RNA-seq based input, specify --library_generation_method trust4.
Bulk RNA-seq
A typical command to run the pipeline from bulk RNA-seq fastq files is:
nextflow run nf-core/airrflow \-profile <docker/singularity/podman/shifter/charliecloud/conda/institute> \--mode fastq \--input input_samplesheet.tsv \--library_generation_method trust4 \--outdir resultsSingle-cell RNA-seq
A typical command to run the pipeline from single-cell RNA-seq fastq files is:
nextflow run nf-core/airrflow \-profile <docker/singularity/podman/shifter/charliecloud/conda/institute> \--mode fastq \--input input_samplesheet.tsv \--library_generation_method trust4 \--umi_read R1 \--cell_barcode_read R1 \--read_format bc:0:15,um:16:27 \--outdir results- If UMI’s are present, the read containing them must be specified using the
--umi_readparameter. - The
--read_formatparameter can be used to specify the Cell Barcode and UMI position within the reads (see TRUST4 docs). For scRNA-seq with 10X Genomics the R1 read usually contains both the cell barcode (barcode) and UMI. So we specify “R1” for both--umi_readand--cell_barcode_read, and the positions of both the cell barcode and UMI with the--read_formatparameter as in the example (“bc:0:15,um:16:27”). Then specify the R1 read in the filename_R1 column of the samplesheet, and the read containing the actual sequence (usually R2) in the filename_R2 column of the samplesheet.
Important considerations for novel allele detection and genotyping
A key step in analyzing BCR sequences involves assigning the germline V, D and J gene alleles to each sequence by matching against a database of known germline V(D)J alleles. However, analyzed individuals can have alleles not present in the databases (novel alleles), which if undetected can inflate the SHM rates. Additionally, genotyping, i.e. identifying the set of alleles that an individual carries for each gene, can help correct ambiguous V(D)J assignments for individual sequences.
nf-core/airrflow includes optional steps to do IG loci novel allele detection, genotype inference and V(D)J allele assignments correction using TIgGER.
These steps only support targeted BCR sequences for now. In addition, due to the large read coverage needed for the algorithm, it does not work well on single-cell BCRs which usually not have enough read coverage.
Genotyping related flags in nf-core/airrflow pipeline
--genotyping: Perform TIgGER novel allele detection and genotype inference if it is set to betrue. It isfalseby default.--single_clone_representative: If it is set to betrue, Keep only one representative sequence per clone for future genotype infernece to reduce the impact of clonal expansion and somatic hypermutation. If--genotypingistrue,single_clone_representativeistrueby default.--genotyping_clonal_threshold: Threshold for determining if two sequences come from the same clone or not while inferring clones to find single clone representative. Default value is 0.2.--novel_allele_inference: whether to perform TIgGER novel allele inference. If--genotypingistrue,--single_clone_representativeistrueby default.
Important considerations for clonal analysis
An important step in the analysis of AIRR sequencing data is inferring B cell and T cell clones, or clonal groups, sometimes also called clonotypes. These are cells that are derived from the same progenitor cell through clonal expansion. For T cells, this definition is more strict as T cells do not undergo somatic hypermutation, so the TCRs from T cells in the same clone should be identical. For B cells, on the other hand, the BCRs from cells in the same clone can differ due to somatic hypermutation. They also can have a variety of isotypes.
There are two crucial considerations when defining clonal groups with nf-core/airrflow: across which samples should clonal groups be defined, and what should be the clonal threshold, i.e. how different can these receptors be, so that these are assigned to the same clonal group. These are discussed in detail in the following sections.
Defining clonal groups across samples
Often times we want to analyze clonal groups from the same individual or animal model across time, different conditions or across samples extracted from different tissues. To ensure that the same clone ID (field clone_id in the output AIRR rearrangement file) is assigned to the same BCR / TCR clone across these conditions to be able to track the clones, the clonal inference step should be done pulling the sequences from these samples together. This is why, by default, nf-core/airrflow uses the subject_id column to group samples prior to defining clonal groups, so it is important to set the exact same subject ID to samples from the same individual across different conditions.
The sample grouping can also be controlled with the --cloneby parameter, by providing the name of the column containing the group information that should be used to pull the samples together before defining clonal groups (samples or rows with the same string in this column will be grouped together). You can create a new column if you wish for this purpose.
Clonal inference method
nf-core/airrflow utilizes the Hierarchical clustering method in the SCOPer Immcantation tool to infer clonal groups by default, which initially partitions the BCR / TCR sequences according to V gene, J gene and junction length. Then, it defines clonal groups within each partition by performing hierarchical clustering of the sequences within a partition and cutting the clusters according to an automatically detected or user-defined threshold. More details about this method can be found on the respective SCOPer vignette. Details on how to determine the clonal threshold can be found in the next section.
Setting a clonal threshold
The clonal threshold can also be customized through the --clonal_threshold parameter. The clonal threshold specifies how different two BCRs can be so that are assigned to the same clonal group. The value is specified in length-normalized hamming distance across the BCR junction regions. By default, --clonal_threshold is set to be ‘auto’, allowing the clonal threshold to be determined automatically using a method included in the SHazaM Immcantation tool. You can read more details about the method in the SHazaM vignette.
For BCR data, we recommend using this default setting initially. After running the pipeline, you can review the automatically calculated threshold in the find_threshold report to make sure it is fitting the data appropriately. If the threshold is unsatisfactory, you can re-run the pipeline with a manually specified threshold (e.g. --clonal_threshold 0.1) that is appropriate for your data. For a low number of sequences that are insufficient to satisfactorily determine a threshold with this method, we generally recommend a threshold of 0.1 (length-normalized Hamming distance of nearest neighbors) for human BCR data.
Since TCRs do not undergo somatic hypermutation, TCR clones are defined strictly by identical junction regions. For this reason, the --clonal_threshold parameter should be set to 0 for TCR data.
Including BCR lineage tree computation
BCR lineage tree computation is performed using the Dowser Immcantation package. This step is skipped by default because it can be time-consuming depending on the size of the input data and the size of the clonal groups. To enable lineage tree computation, add the --lineage_trees parameter set to true. You can easily add lineage tree computation to a previous analysis by re-running the pipeline with the -resume flag so all the previous analysis steps are cached and not recomputed.
Dowser supports different methods for the lineage tree computation, raxml is the default but you can set other methods with the --lineage_tree_builder parameter, and provide the software executable with the --lineage_tree_exec parameter.
Core Nextflow arguments
These options are part of Nextflow and use a single hyphen (pipeline parameters use a double-hyphen)
-profile
Use this parameter to choose a configuration profile. Profiles can give configuration presets for different compute environments.
Several generic profiles are bundled with the pipeline which instruct the pipeline to use software packaged using different methods (Docker, Singularity, Podman, Shifter, Charliecloud, Apptainer, Conda) - see below.
We highly recommend the use of Docker or Singularity containers for full pipeline reproducibility. Conda is not supported for this pipeline.
The pipeline also dynamically loads configurations from https://github.com/nf-core/configs when it runs, making multiple config profiles for various institutional clusters available at run time. For more information and to check if your system is supported, please see the nf-core/configs documentation.
Note that multiple profiles can be loaded, for example: -profile test,docker - the order of arguments is important!
They are loaded in sequence, so later profiles can overwrite earlier profiles.
If -profile is not specified, the pipeline will run locally and expect all software to be installed and available on the PATH. This is not recommended, since it can lead to different results on different machines dependent on the computer environment.
test- A profile with a complete configuration for automated testing
- Includes links to test data so needs no other parameters
docker- A generic configuration profile to be used with Docker
singularity- A generic configuration profile to be used with Singularity
podman- A generic configuration profile to be used with Podman
shifter- A generic configuration profile to be used with Shifter
charliecloud- A generic configuration profile to be used with Charliecloud
apptainer- A generic configuration profile to be used with Apptainer
wave- A generic configuration profile to enable Wave containers. Use together with one of the above (requires Nextflow
24.03.0-edgeor later).
- A generic configuration profile to enable Wave containers. Use together with one of the above (requires Nextflow
conda- A generic configuration profile to be used with Conda. Please only use Conda as a last resort i.e. when it’s not possible to run the pipeline with Docker, Singularity, Podman, Shifter, Charliecloud, or Apptainer.
-resume
Specify this when restarting a pipeline. Nextflow will use cached results from any pipeline steps where the inputs are the same, continuing from where it got to previously. For input to be considered the same, not only the names must be identical but the files’ contents as well. For more info about this parameter, see this blog post.
You can also supply a run name to resume a specific run: -resume [run-name]. Use the nextflow log command to show previous run names.
-c
Specify the path to a specific config file (this is a core Nextflow command). See the nf-core website documentation for more information.
Custom configuration
Resource requests
Whilst the default requirements set within the pipeline will hopefully work for most people and with most input data, you may find that you want to customise the compute resources that the pipeline requests. Each step in the pipeline has a default set of requirements for number of CPUs, memory and time. For most of the pipeline steps, if the job exits with any of the error codes specified here it will automatically be resubmitted with higher resources request (2 x original, then 3 x original). If it still fails after the third attempt then the pipeline execution is stopped.
To change the resource requests, please see the max resources and customise process resources section of the nf-core website.
Custom Containers
In some cases, you may wish to change the container or conda environment used by a pipeline steps for a particular tool. By default, nf-core pipelines use containers and software from the biocontainers or bioconda projects. However, in some cases the pipeline specified version maybe out of date.
To use a different container from the default container or conda environment specified in a pipeline, please see the updating tool versions section of the nf-core website.
Custom Tool Arguments
A pipeline might not always support every possible argument or option of a particular tool used in pipeline. Fortunately, nf-core pipelines provide some freedom to users to insert additional parameters that the pipeline does not include by default.
To learn how to provide additional arguments to a particular tool of the pipeline, please see the customising tool arguments section of the nf-core website.
nf-core/configs
In most cases, you will only need to create a custom config as a one-off but if you and others within your organisation are likely to be running nf-core pipelines regularly and need to use the same settings regularly it may be a good idea to request that your custom config file is uploaded to the nf-core/configs git repository. Before you do this please can you test that the config file works with your pipeline of choice using the -c parameter. You can then create a pull request to the nf-core/configs repository with the addition of your config file, associated documentation file (see examples in nf-core/configs/docs), and amending nfcore_custom.config to include your custom profile.
See the main Nextflow documentation for more information about creating your own configuration files.
If you have any questions or issues please send us a message on Slack on the #configs channel.
Running in the background
Nextflow handles job submissions and supervises the running jobs. The Nextflow process must run until the pipeline is finished.
The Nextflow -bg flag launches Nextflow in the background, detached from your terminal so that the workflow does not stop if you log out of your session. The logs are saved to a file.
Alternatively, you can use screen / tmux or similar tool to create a detached session which you can log back into at a later time.
Some HPC setups also allow you to run nextflow within a cluster job submitted your job scheduler (from where it submits more jobs).
Nextflow memory requirements
In some cases, the Nextflow Java virtual machines can start to request a large amount of memory.
We recommend adding the following line to your environment to limit this (typically in ~/.bashrc or ~./bash_profile):
NXF_OPTS='-Xms1g -Xmx4g'