nf-core/genomeqc
Compare the quality of multiple genomes, along with their annotations.
Introduction
nf-core/genomeqc is a bioinformatics pipeline that compares the quality of multiple genomes, along with their annotations.
The pipeline takes a list of genomes and annotations (from local files or ncbi accessions), and runs commonly used tools to assess their quality.
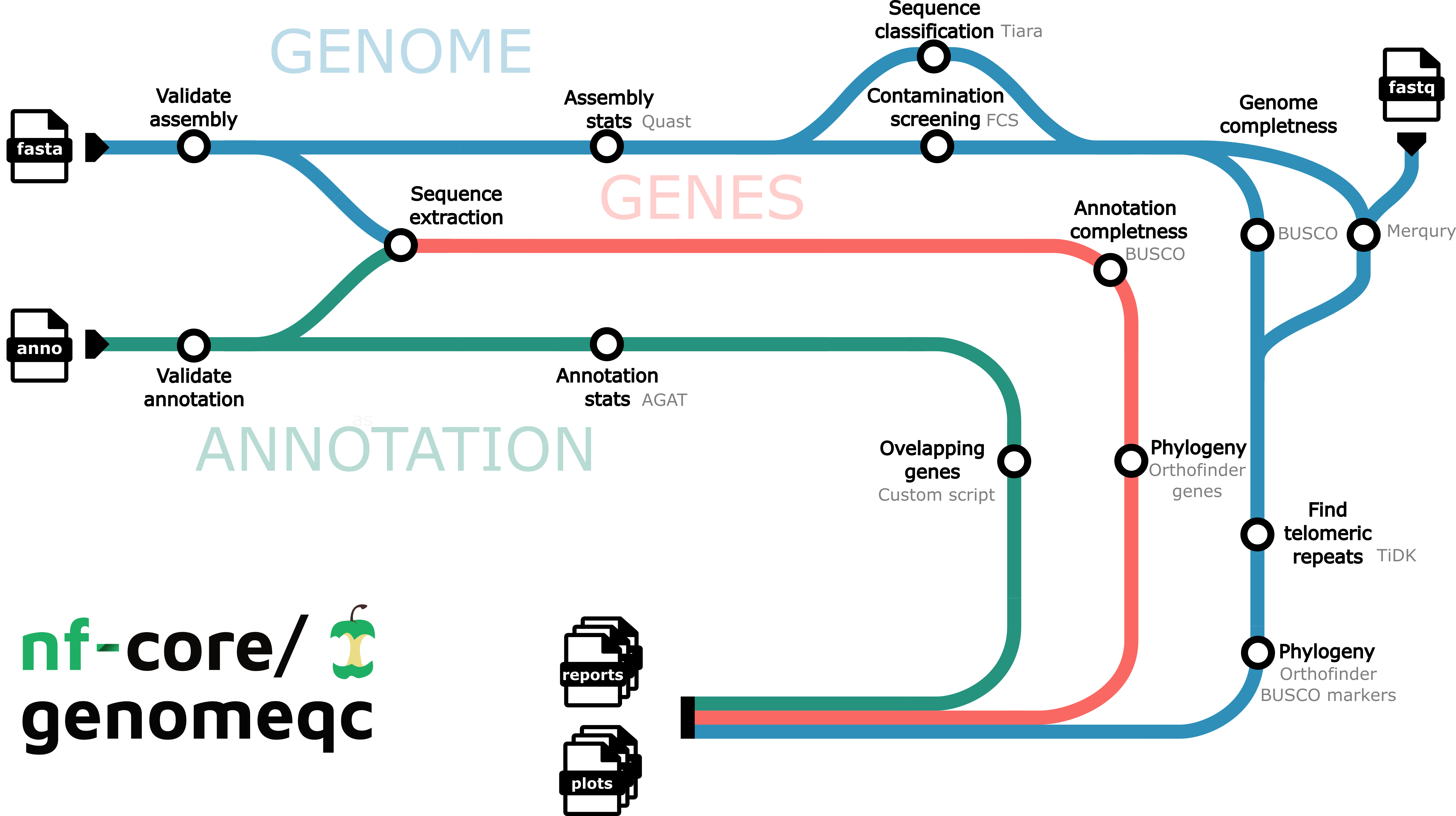
- Downloads the genome and gene annotation files from NCBI: NCBI genome download - Or provide your own genomes and annotations.
- Describes genome assembly:
- BUSCO: Evaluates genome/proteome completeness based on single copy markers.
- BUSCO Ideogram: Plots the location of BUSCO markers on the assembly.
- Merqury (optional): Evaluates genome completeness based on sequencing reads.
- tidk (optional): Identifies and visualises telomeric repeats.
- QUAST: Computes contiguity and integrity statistics: N50, N90, GC%, number of sequences.
- Contamination screening:
- FCS-GX: Detection and removal of foreign organisms contamination.
- FCS-adaptor: Detection and removal of adaptor and vector contamination.
- Tiara: DNA sequence classification.
- More options…
- Describes annotation :
- AGAT: Number of genes, features, length…
- Gene Overlaps: Finds the number of overlapping genes.
- Extracts longest protein isoform: GffRead.
- Finds orthologous genes: Orthofinder.
- Plots an orthology-based - if annotation is given - or BUSCO marker-based - if no annotation is given - phylogenetic tree with summary statistics: Tree Summary
- Summary with HTML and excel custom reports.
- Summary with MultiQC.
The pipeline outputs an executable that launches a shiny app with the tree plot and the summary statistics. The parameters of the plot can be modified, and summary statistics can be added or removed in real time. Once the plot has been adjusted, it can be saved as png/svg. The tree plot needs at least three assemblies to be plotted, and it servers as a quick overview of the quality of all assemblies.
If no annotation is given as input, the pipeline will ignore the steps involving gene statistics.
We strongly suggest users to specify the lineage using the --busco_lineage parameter, as setting the lineage to auto (default value) might cause problems with BUSCO during the lineage determination step.
BUSCO Ideogram will only plot those chromosomes -or scaffolds- that contain at least one single copy marker.
Usage
If you are new to Nextflow and nf-core, please refer to this page on how to set-up Nextflow. Make sure to test your setup with -profile test before running the workflow on actual data.
First, prepare an input samplesheet in csv format (e.g. samplesheet.csv). You can prepare your sampplesheet using:
1. Local files
Simply point out to your local genome assembly and annotation (in FASTA and GFF format, respectively) using the fasta and gff fields:
species,fasta,gffspecies_1,/path/to/genome1.fasta,/path/to/annotation1.gff3species_2,/path/to/genome2.fasta,/path/to/annotation2.gff3species_3,/path/to/genome3.fasta,/path/to/annotation3.gff32. ncbi accessions
Additionally, you can run the pipeline providing ncbi accessions (RefSeq or GenBank, depeding on the mode you wish to run) in the ncbi field:
species,ncbispecies_1,GCF_000000001.1species_2,GCF_000000002.1species_3,GCF_000000003.13. Both
You can combine both input types in the same samplesheet:
species,ncbi,fasta,gffspecies_1,GCF_000000001.1species_2,,/path/to/genome2.fasta,/path/to/annotation2.gff3species_3,GCF_000000003.1species_4,,/path/to/genome4.fasta,/path/to/annotation4.gff3Run the pipeline
Run the pipeline using:
nextflow run nf-core/genomeqc \ -profile <docker/singularity/.../institute> \ --input samplesheet.csv \ --outdir <OUTDIR>You can run the pipeline using a test profile and docker:
nextflow run nf-core/genomeqc -profile test,docker --outdir ./resultsPlease provide pipeline parameters via the CLI or Nextflow -params-file option. Custom config files including those provided by the -c Nextflow option can be used to provide any configuration except for parameters; see docs.
For more details and further functionality, please refer to the usage documentation and the parameter documentation.
Pipeline output
To see the results of an example test run with a full size dataset refer to the results tab on the nf-core website pipeline page. For more details about the output files and reports, please refer to the output documentation.
Credits
nf-core/genomeqc was originally written by Chris Wyatt and Fernando Duarte at the University College London.
We thank the following people for their extensive assistance in the development of this pipeline:
- Mahesh Binzer-Panchal (National Bioinformatics Infrastructure Sweden)
- Usman Rashid (The New Zealand Institute for Plant and Food Research)
- Lauren Huet (Schmidt Ocean Institute)
- Stephen Turner (Colossal Biosciences)
- Felipe Perez Cobos (Institute of Agrifood Research and Technology)
- Simon Murray (Nextflow Ambassador)
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don’t hesitate to get in touch on the Slack #genomeqc channel (you can join with this invite).
Citations
If you use nf-core/genomeqc for your analysis, please cite it using the following doi: https://doi.org/10.48546/WORKFLOWHUB.WORKFLOW.2181.1, until the paper is accepted in a peer reviwed journal.
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md file.
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.