nf-core/isoseq
Genome annotation with PacBio Iso-Seq. Takes raw subreads as input, generate Full Length Non Chemiric (FLNC) sequences and produce a bed annotation.
1.1.4). The latest
stable release is
2.0.0
.
Introduction
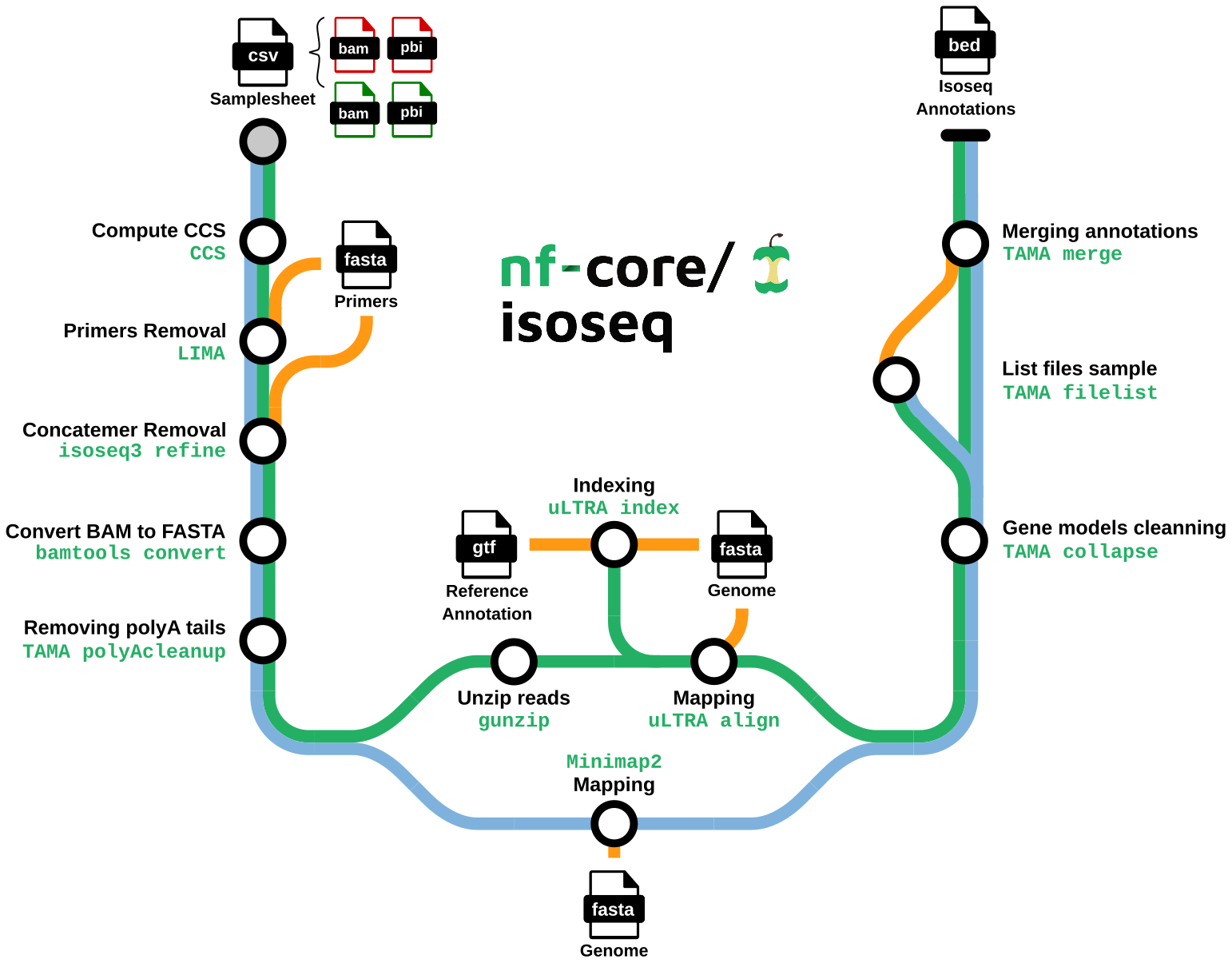
nf-core/isoseq is a bioinformatics best-practice analysis pipeline for Isoseq gene annotation with uLTRA and TAMA. Starting from raw isoseq subreads, the pipeline:
-
Generates the Circular Consensus Sequences (CSS)
-
Clean and polish CCS to create Full Length Non Chimeric (FLNC) reads
-
Maps FLNCs on the genome
-
Define and clean gene models
The pipeline is built using Nextflow, a workflow tool to run tasks across multiple compute infrastructures in a very portable manner. It uses Docker/Singularity containers making installation trivial and results highly reproducible. The Nextflow DSL2 implementation of this pipeline uses one container per process which makes it much easier to maintain and update software dependencies. Where possible, these processes have been submitted to and installed from nf-core/modules in order to make them available to all nf-core pipelines, and to everyone within the Nextflow community!
On release, automated continuous integration tests run the pipeline on a full-sized dataset on the AWS cloud infrastructure. This ensures that the pipeline runs on AWS, has sensible resource allocation defaults set to run on real-world datasets, and permits the persistent storage of results to benchmark between pipeline releases and other analysis sources. The results obtained from the full-sized test can be viewed on the nf-core website.
Pipeline summary
- Generate CCS consensuses from raw isoseq subreads (
PBCCS) - Remove primer sequences from consensuses (
LIMA) - Detect and remove chimeric reads (
ISOSEQ3 REFINE) - Convert bam file into fasta file (
BAMTOOLS CONVERT) - Select reads with a polyA tail and trim it (
GSTAMA_POLYACLEANUP) - uLTRA path: decompress FLNCs (
GUNZIP) - uLTRA path: index
GTFfile for mapping (uLTRA) - Map consensuses on the reference genome (
MINIMAP2oruLTRA) - Clean gene models (
TAMA collapse) - Merge annotations by sample (
TAMA merge)
Quick Start
-
Install
Nextflow(>=22.10.1) -
Install any of
Docker,Singularity(you can follow this tutorial),Podman,ShifterorCharliecloudfor full pipeline reproducibility (you can useCondaboth to install Nextflow itself and also to manage software within pipelines. Please only use it within pipelines as a last resort; see docs). -
Download the pipeline and test it on a minimal dataset with a single command:
nextflow run nf-core/isoseq -profile test,YOURPROFILE --outdir <OUTDIR>Note that some form of configuration will be needed so that Nextflow knows how to fetch the required software. This is usually done in the form of a config profile (
YOURPROFILEin the example command above). You can chain multiple config profiles in a comma-separated string.- The pipeline comes with config profiles called
docker,singularity,podman,shifter,charliecloudandcondawhich instruct the pipeline to use the named tool for software management. For example,-profile test,docker. - Please check nf-core/configs to see if a custom config file to run nf-core pipelines already exists for your Institute. If so, you can simply use
-profile <institute>in your command. This will enable eitherdockerorsingularityand set the appropriate execution settings for your local compute environment. - If you are using
singularity, please use thenf-core downloadcommand to download images first, before running the pipeline. Setting theNXF_SINGULARITY_CACHEDIRorsingularity.cacheDirNextflow options enables you to store and re-use the images from a central location for future pipeline runs. - If you are using
conda, it is highly recommended to use theNXF_CONDA_CACHEDIRorconda.cacheDirsettings to store the environments in a central location for future pipeline runs.
- The pipeline comes with config profiles called
-
Start running your own analysis!
nextflow run nf-core/isoseq --input samplesheet.csv --outdir <OUTDIR> --genome <GENOME NAME (e.g. GRCh37)> --primers <PRIMER FASTA> -profile <docker/singularity/podman/shifter/charliecloud/conda/institute>
Documentation
The nf-core/isoseq pipeline comes with documentation about the pipeline usage, parameters and output.
Credits
nf-core/isoseq was originally written by Sébastien Guizard.
We thank the following people for their extensive assistance in the development of this pipeline:
- Thanks to Jose Espinosa-Carrasco, Daniel Schreyer and Gisela Gabernet for their reviews and contributions
- Kristoffer Sahlin for
uLTRAand the help he provided - Richard Kuo (Wobble Genomics) for his valuable advices on isoseq analysis
- The Workpackage 2 of GENE-SWitCH Project for their fruitful discussions and remarks
- Mick Watson group for their support
- The nf-core community for their help in the development of this pipeline
- James A. Fellows Yates & nf-core for the metro map style components for pipeline graph
This pipeline has been developed as part of the GENE-SWitCH project. This project has received funding from the European Union’s Horizon 2020 Research and Innovation Programme under the grant agreement n° 817998.
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don’t hesitate to get in touch on the Slack #isoseq channel (you can join with this invite).
Citations
- Isoseq3
- TAMA: Kuo, R.I., Cheng, Y., Zhang, R. et al. Illuminating the dark side of the human transcriptome with long read transcript sequencing. BMC Genomics 21, 751 (2020). 10.1186/s12864-020-07123-7
- Minimap2: Li, H. (2018). Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics, 34:3094-3100., Li, H. (2021). New strategies to improve minimap2 alignment accuracy. Bioinformatics, 37:4572-4574. 10.1093/bioinformatics/btab705
- uLTRA: Kristoffer Sahlin, Veli Mäkinen, Accurate spliced alignment of long RNA sequencing reads, Bioinformatics, Volume 37, Issue 24, 15 December 2021, Pages 4643–4651. 10.1093/bioinformatics/btab540
- Samtools: Danecek P, Bonfield JK, Liddle J, Marshall J, Ohan V, Pollard MO, Whitwham A, Keane T, McCarthy SA, Davies RM, Li H, Twelve years of SAMtools and BCFtools, GigaScience (2021) 10(2) giab008. 10.1093/gigascience/giab007
- MultiQC: Philip Ewels, Måns Magnusson, Sverker Lundin, Max Käller, MultiQC: summarize analysis results for multiple tools and samples in a single report, Bioinformatics, Volume 32, Issue 19, 1 October 2016, Pages 3047–3048. 10.1093/bioinformatics/btw354
- samtools: Danecek P, Bonfield JK, Liddle J, Marshall J, Ohan V, Pollard MO, Whitwham A, Keane T, McCarthy SA, Davies RM, Li H, Twelve years of SAMtools and BCFtools, GigaScience (2021) 10(2) 10.1093/gigascience/giab008
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md file.
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.