nf-core/diaproteomics
Automated quantitative analysis of DIA proteomics mass spectrometry measurements.
1.1.0). The latest
stable release is
1.2.4
.
22.10.6.
Learn more.
Introduction
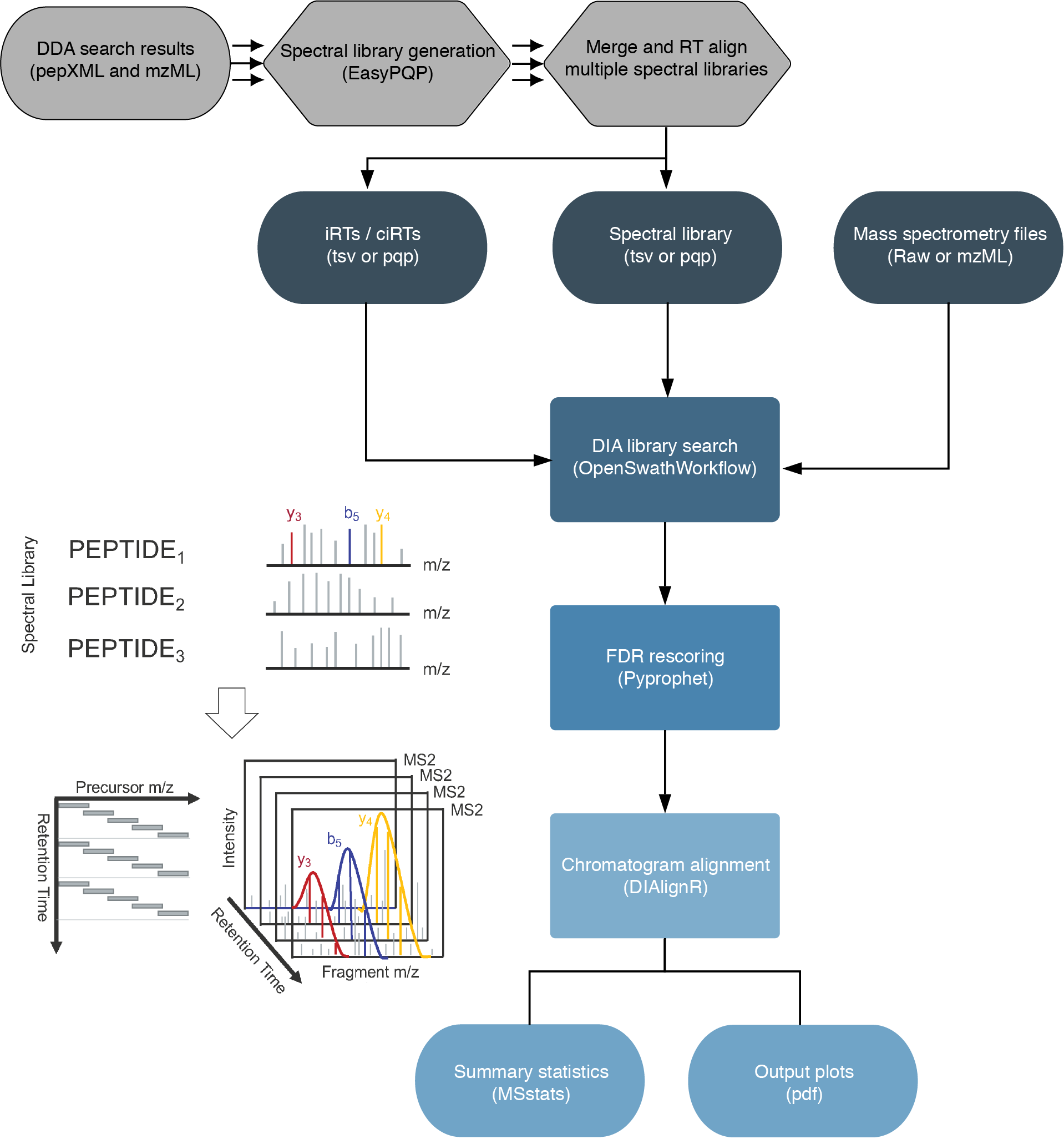
nfcore/diaproteomics is a bioinformatics analysis pipeline used for quantitative processing of data independant (DIA) proteomics data.
The workflow is based on the OpenSwathWorkflow for SWATH-MS proteomic data. DIA RAW files (mzML) serve as inputs and library search is performed based on a given input spectral library. Optionally, spectral libraries can be generated (EasyPQP) from multiple matched DDA measurments and respective search results. Generated libraries can then further be aligned applying a pairwise RT alignment and concatenated into a single large library. In the same way internal retention time standarts (irts) can be either supplied or generted by the workflow in order to align library and DIA measurements into the same retention time space. FDR rescoring is applied using Pyprophet based on a competitive target-decoy approach on peakgroup or global peptide and protein level. In a last step DIAlignR for chromatogram alignment and quantification is carried out and a csv of peptide quantities, MSstats based protein statistics and several visualisations are exported.
Quick Start
-
Install
nextflow -
Install any of
Docker,SingularityorPodmanfor full pipeline reproducibility (please only useCondaas a last resort; see docs) -
Download the pipeline and test it on a minimal dataset with a single command:
nextflow run nf-core/diaproteomics -profile test,<docker/singularity/podman/conda/institute>Please check nf-core/configs to see if a custom config file to run nf-core pipelines already exists for your Institute. If so, you can simply use
-profile <institute>in your command. This will enable eitherdockerorsingularityand set the appropriate execution settings for your local compute environment. -
Start running your own analysis!
nextflow run nf-core/diaproteomics -profile <docker/singularity/podman/conda/institute> --input 'sample_sheet.tsv' --input_spectral_library 'library_sheet.tsv' --irts 'irt_sheet.tsv'OR optionally:
nextflow run nf-core/diaproteomics -profile <docker/singularity/podman/conda/institute> --input 'sample_sheet.tsv' --generate_spectral_library --input_sheet_dda 'dda_sheet.tsv' --generate_pseudo_irts --merge_libraries --align_libraries
See usage docs for all of the available options when running the pipeline.
Documentation
The nf-core/diaproteomics pipeline comes with documentation about the pipeline: usage and output.
Credits
nf-core/diaproteomics was originally written by Leon Bichmann.
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don’t hesitate to get in touch on the Slack #diaproteomics channel (you can join with this invite).
Citation
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x. ReadCube: Full Access Link