nf-core/rnaseq
RNA sequencing analysis pipeline using STAR, RSEM, HISAT2 or Salmon with gene/isoform counts and extensive quality control.
3.5). The latest stable release is3.26.0.Introduction
This document describes the output produced by the pipeline. Most of the plots are taken from the MultiQC report generated from the full-sized test dataset for the pipeline using a command similar to the one below:
nextflow run nf-core/rnaseq -profile test_full,<docker/singularity/institute>The directories listed below will be created in the results directory after the pipeline has finished. All paths are relative to the top-level results directory.
Pipeline overview
The pipeline is built using Nextflow and processes data using the following steps:
- Preprocessing
- cat - Merge re-sequenced FastQ files
- FastQC - Raw read QC
- UMI-tools extract - UMI barcode extraction
- TrimGalore - Adapter and quality trimming
- BBSplit - Removal of genome contaminants
- SortMeRNA - Removal of ribosomal RNA
- Alignment and quantification
- STAR and Salmon - Fast spliced aware genome alignment and transcriptome quantification
- STAR via RSEM - Alignment and quantification of expression levels
- HISAT2 - Memory efficient splice aware alignment to a reference
- Alignment post-processing
- SAMtools - Sort and index alignments
- UMI-tools dedup - UMI-based deduplication
- picard MarkDuplicates - Duplicate read marking
- Other steps
- StringTie - Transcript assembly and quantification
- BEDTools and bedGraphToBigWig - Create bigWig coverage files
- Quality control
- RSeQC - Various RNA-seq QC metrics
- Qualimap - Various RNA-seq QC metrics
- dupRadar - Assessment of technical / biological read duplication
- Preseq - Estimation of library complexity
- featureCounts - Read counting relative to gene biotype
- DESeq2 - PCA plot and sample pairwise distance heatmap and dendrogram
- MultiQC - Present QC for raw reads, alignment, read counting and sample similiarity
- Pseudo-alignment and quantification
- Salmon - Wicked fast gene and isoform quantification relative to the transcriptome
- Workflow reporting and genomes
- Reference genome files - Saving reference genome indices/files
- Pipeline information - Report metrics generated during the workflow execution
Preprocessing
cat
Output files
fastq/*.merged.fastq.gz: If--save_merged_fastqis specified, concatenated FastQ files will be placed in this directory.
If multiple libraries/runs have been provided for the same sample in the input samplesheet (e.g. to increase sequencing depth) then these will be merged at the very beginning of the pipeline in order to have consistent sample naming throughout the pipeline. Please refer to the usage documentation to see how to specify these samples in the input samplesheet.
FastQC
Output files
fastqc/*_fastqc.html: FastQC report containing quality metrics.*_fastqc.zip: Zip archive containing the FastQC report, tab-delimited data file and plot images.
NB: The FastQC plots in this directory are generated relative to the raw, input reads. They may contain adapter sequence and regions of low quality. To see how your reads look after adapter and quality trimming please refer to the FastQC reports in the
trimgalore/fastqc/directory.
FastQC gives general quality metrics about your sequenced reads. It provides information about the quality score distribution across your reads, per base sequence content (%A/T/G/C), adapter contamination and overrepresented sequences. For further reading and documentation see the FastQC help pages.
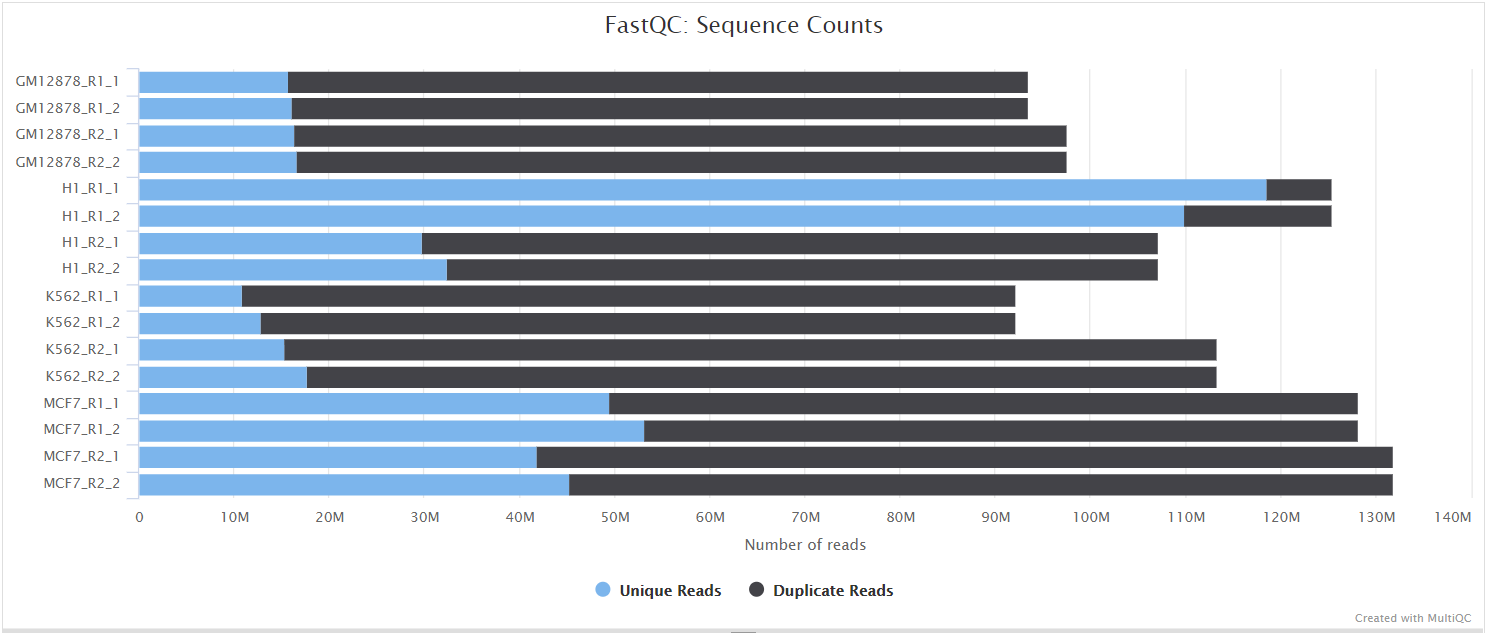
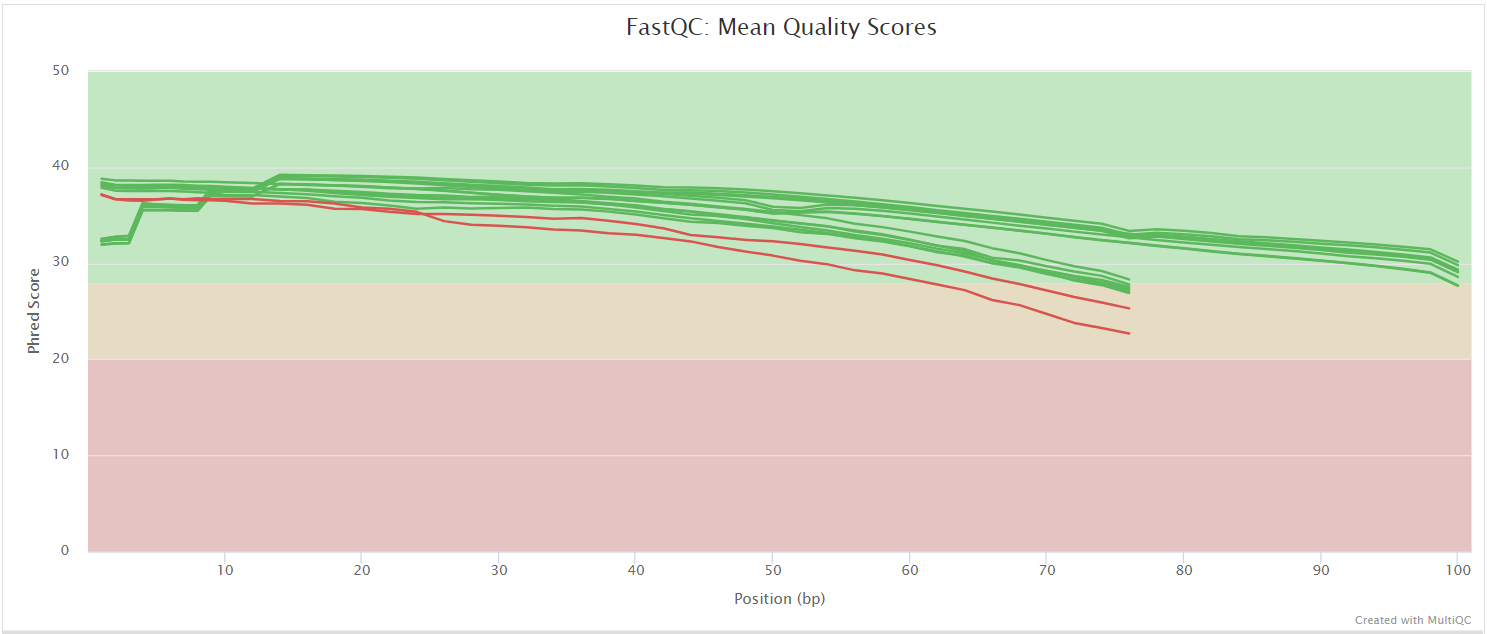
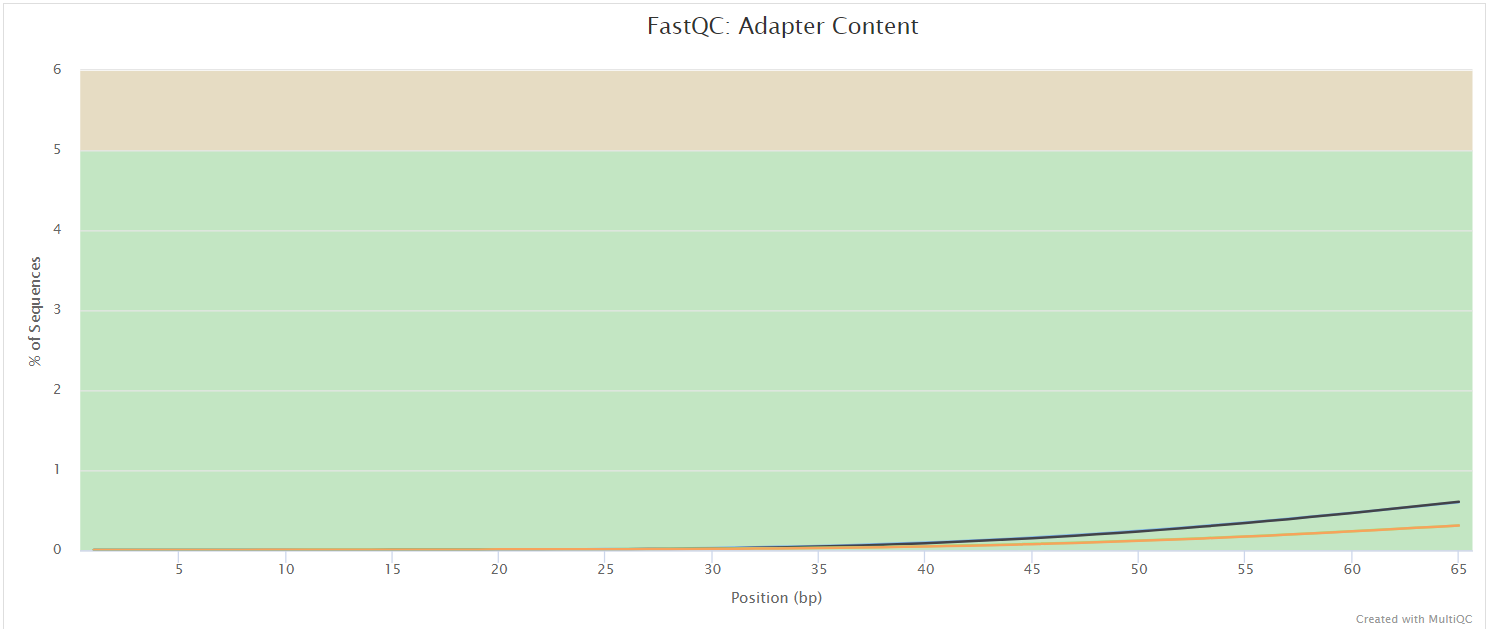
UMI-tools extract
Output files
umitools/*.fastq.gz: If--save_umi_intermedsis specified, FastQ files after UMI extraction will be placed in this directory.*.log: Log file generated by the UMI-toolsextractcommand.
UMI-tools deduplicates reads based on unique molecular identifiers (UMIs) to address PCR-bias. Firstly, the UMI-tools extract command removes the UMI barcode information from the read sequence and adds it to the read name. Secondly, reads are deduplicated based on UMI identifier after mapping as highlighted in the UMI-tools dedup section.
TrimGalore
Output files
trimgalore/*.fq.gz: If--save_trimmedis specified, FastQ files after adapter trimming will be placed in this directory.*_trimming_report.txt: Log file generated by Trim Galore!.
trimgalore/fastqc/*_fastqc.html: FastQC report containing quality metrics for read 1 (and read2 if paired-end) after adapter trimming.*_fastqc.zip: Zip archive containing the FastQC report, tab-delimited data file and plot images.
Trim Galore! is a wrapper tool around Cutadapt and FastQC to peform quality and adapter trimming on FastQ files. By default, Trim Galore! will automatically detect and trim the appropriate adapter sequence.
NB: TrimGalore! will only run using multiple cores if you are able to use more than > 5 and > 6 CPUs for single- and paired-end data, respectively. The total cores available to TrimGalore! will also be capped at 4 (7 and 8 CPUs in total for single- and paired-end data, respectively) because there is no longer a run-time benefit. See release notes and discussion whilst adding this logic to the nf-core/atacseq pipeline.
BBSplit
Output files
bbsplit/*.fastq.gz: If--save_bbsplit_readsis specified FastQ files split by reference will be saved to the results directory. Reads from the main reference genome will be named “primary.fastq.gz”. Reads from contaminating genomes will be named “<SHORT_NAME>.fastq.gz” where<SHORT_NAME>is the first column in--bbsplit_fasta_listthat needs to be provided to initially build the index.*.txt: File containing statistics on how many reads were assigned to each reference.
BBSplit is a tool that bins reads by mapping to multiple references simultaneously, using BBMap. The reads go to the bin of the reference they map to best. There are also disambiguation options, such that reads that map to multiple references can be binned with all of them, none of them, one of them, or put in a special “ambiguous” file for each of them.
This functionality would be especially useful, for example, if you have mouse PDX samples that contain a mixture of human and mouse genomic DNA/RNA and you would like to filter out any mouse derived reads.
The BBSplit index will have to be built at least once with this pipeline by providing --bbsplit_fasta_list which has to be a file containing 2 columns: short name and full path to reference genome(s):
mm10,/path/to/mm10.faecoli,/path/to/ecoli.fasarscov2,/path/to/sarscov2.faYou can save the index by using the --save_reference parameter and then provide it via --bbsplit_index for future runs. As described in the Output files dropdown box above the FastQ files relative to the main reference genome will always be called *primary*.fastq.gz.
SortMeRNA
Output files
sortmerna/*.fastq.gz: If--save_non_ribo_readsis specified, FastQ files containing non-rRNA reads will be placed in this directory.*.log: Log file generated by SortMeRNA with information regarding reads that matched the reference database(s).
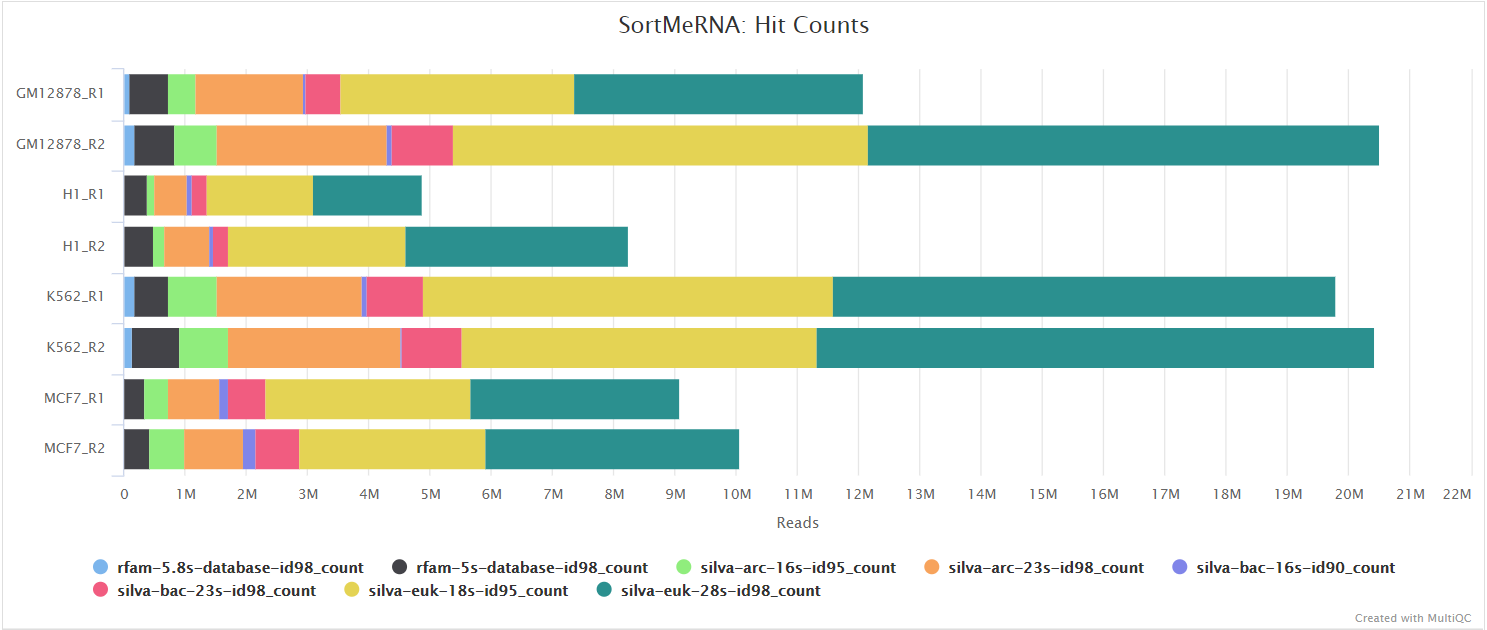
When --remove_ribo_rna is specified, the pipeline uses SortMeRNA for the removal of ribosomal RNA. By default, rRNA databases defined in the SortMeRNA GitHub repo are used. You can see an example in the pipeline Github repository in assets/rrna-default-dbs.txt which is used by default via the --ribo_database_manifest parameter. Please note that commercial/non-academic entities require licensing for SILVA for these default databases.
Alignment and quantification
STAR and Salmon
Output files
star_salmon/*.Aligned.out.bam: If--save_align_intermedsis specified the original BAM file containing read alignments to the reference genome will be placed in this directory.*.Aligned.toTranscriptome.out.bam: If--save_align_intermedsis specified the original BAM file containing read alignments to the transcriptome will be placed in this directory.
star_salmon/log/*.SJ.out.tab: File containing filtered splice junctions detected after mapping the reads.*.Log.final.out: STAR alignment report containing the mapping results summary.*.Log.outand*.Log.progress.out: STAR log files containing detailed information about the run. Typically only useful for debugging purposes.
star_salmon/unmapped/*.fastq.gz: If--save_unalignedis specified, FastQ files containing unmapped reads will be placed in this directory.
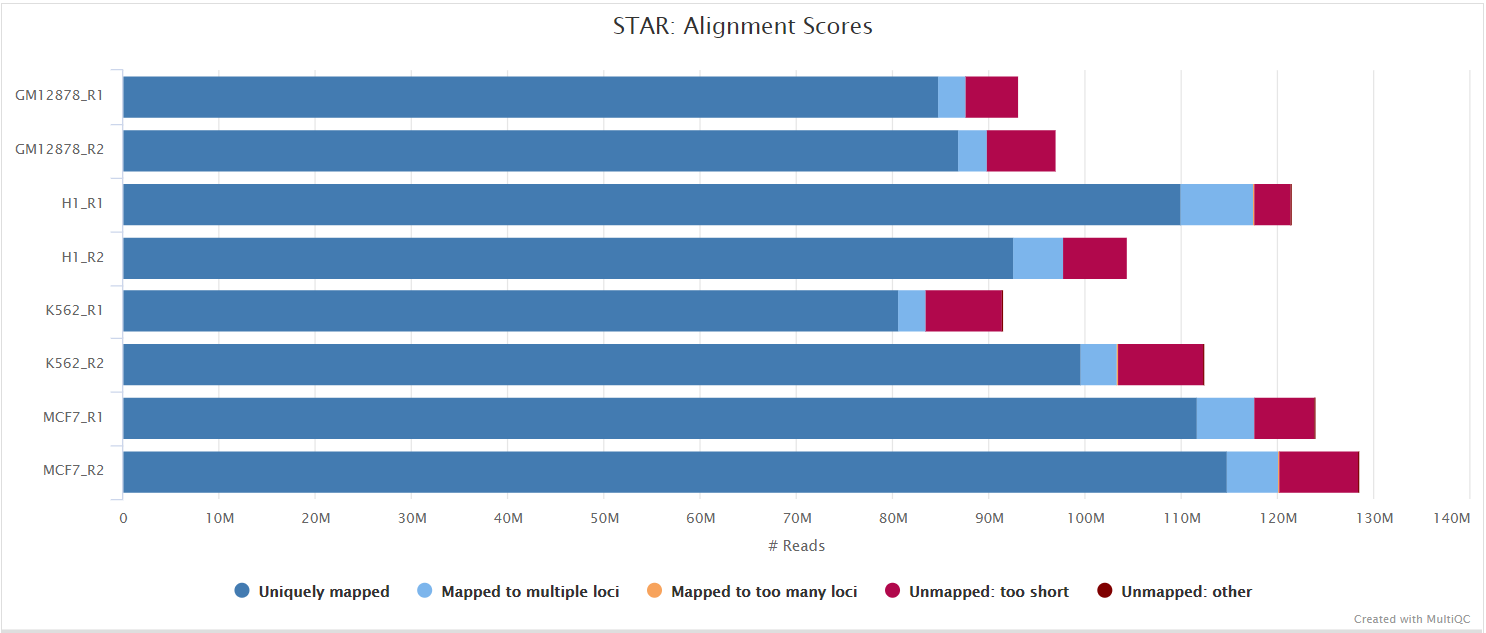
STAR is a read aligner designed for splice aware mapping typical of RNA sequencing data. STAR stands for Spliced Transcripts Alignment to a Reference, and has been shown to have high accuracy and outperforms other aligners by more than a factor of 50 in mapping speed, but it is memory intensive. Using --aligner star_salmon is the default alignment and quantification option.
Salmon from Ocean Genomics is a tool for wicked-fast transcript quantification from RNA-seq data. It requires a set of target transcripts (either from a reference or de-novo assembly) in order to perform quantification. All you need to run Salmon is a FASTA file containing your reference transcripts and a set of FASTA/FASTQ/BAM file(s) containing your reads. The transcriptome-level BAM files generated by STAR are provided to Salmon for downstream quantification. You can of course also provide FASTQ files directly as input to Salmon in order to pseudo-align and quantify your data by providing the --pseudo_aligner salmon parameter. The results generated by the pipeline are exactly the same whether you provide BAM or FASTQ input so please see the Salmon results section for more details.
The STAR section of the MultiQC report shows a bar plot with alignment rates: good samples should have most reads as Uniquely mapped and few Unmapped reads.
STAR via RSEM
Output files
star_rsem/rsem.merged.gene_counts.tsv: Matrix of gene-level raw counts across all samples.rsem.merged.gene_tpm.tsv: Matrix of gene-level TPM values across all samples.rsem.merged.transcript_counts.tsv: Matrix of isoform-level raw counts across all samples.rsem.merged.transcript_tpm.tsv: Matrix of isoform-level TPM values across all samples.*.genes.results: RSEM gene-level quantification results for each sample.*.isoforms.results: RSEM isoform-level quantification results for each sample.*.STAR.genome.bam: If--save_align_intermedsis specified the original BAM file containing read alignments to the reference genome will be placed in this directory.*.transcript.bam: If--save_align_intermedsis specified the original BAM file containing read alignments to the transcriptome will be placed in this directory.
star_rsem/<SAMPLE>.stat/*.cnt,*.model,*.theta: RSEM counts and statistics for each sample.star_rsem/log/*.log: STAR alignment report containing the mapping results summary.
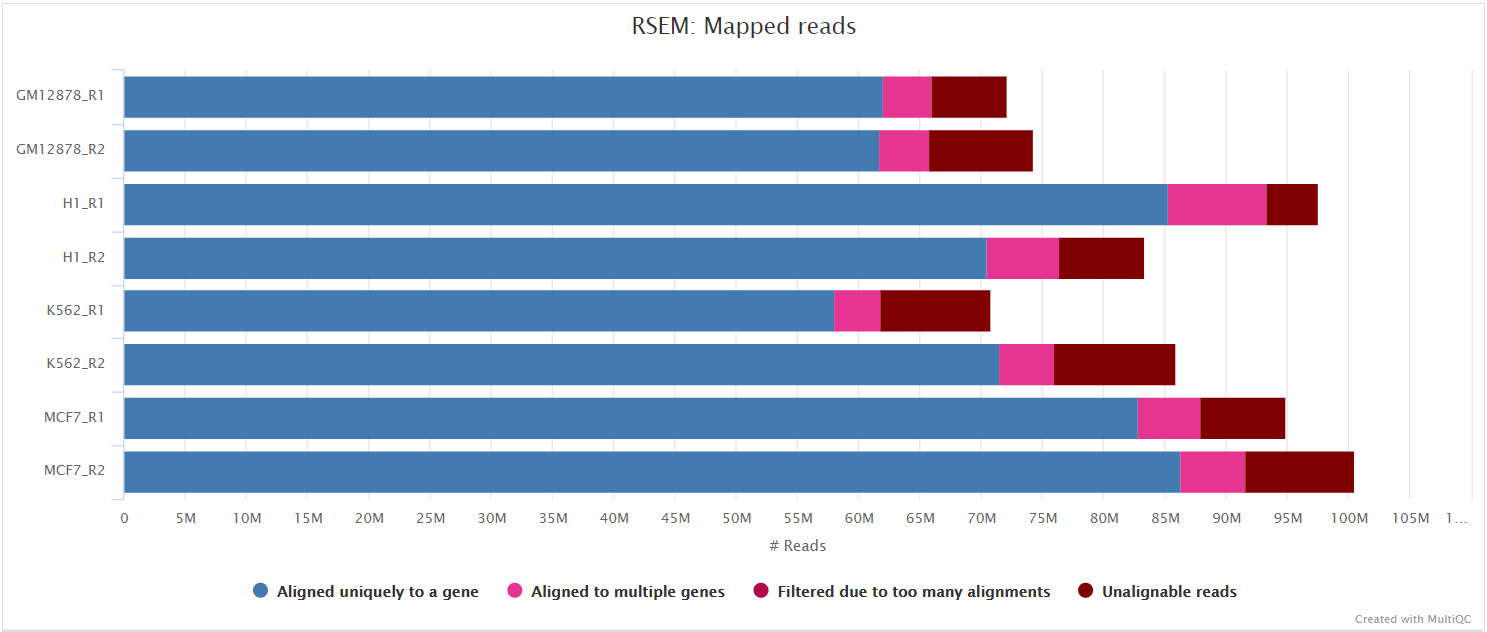
RSEM is a software package for estimating gene and isoform expression levels from RNA-seq data. It has been widely touted as one of the most accurate quantification tools for RNA-seq analysis. RSEM wraps other popular tools to map the reads to the genome (i.e. STAR, Bowtie2, HISAT2; STAR is used in this pipeline) which are then subsequently filtered relative to a transcriptome before quantifying at the gene- and isoform-level. Other advantages of using RSEM are that it performs both the alignment and quantification in a single package and its ability to effectively use ambiguously-mapping reads.
You can choose to align and quantify your data with RSEM by providing the --aligner star_rsem parameter.
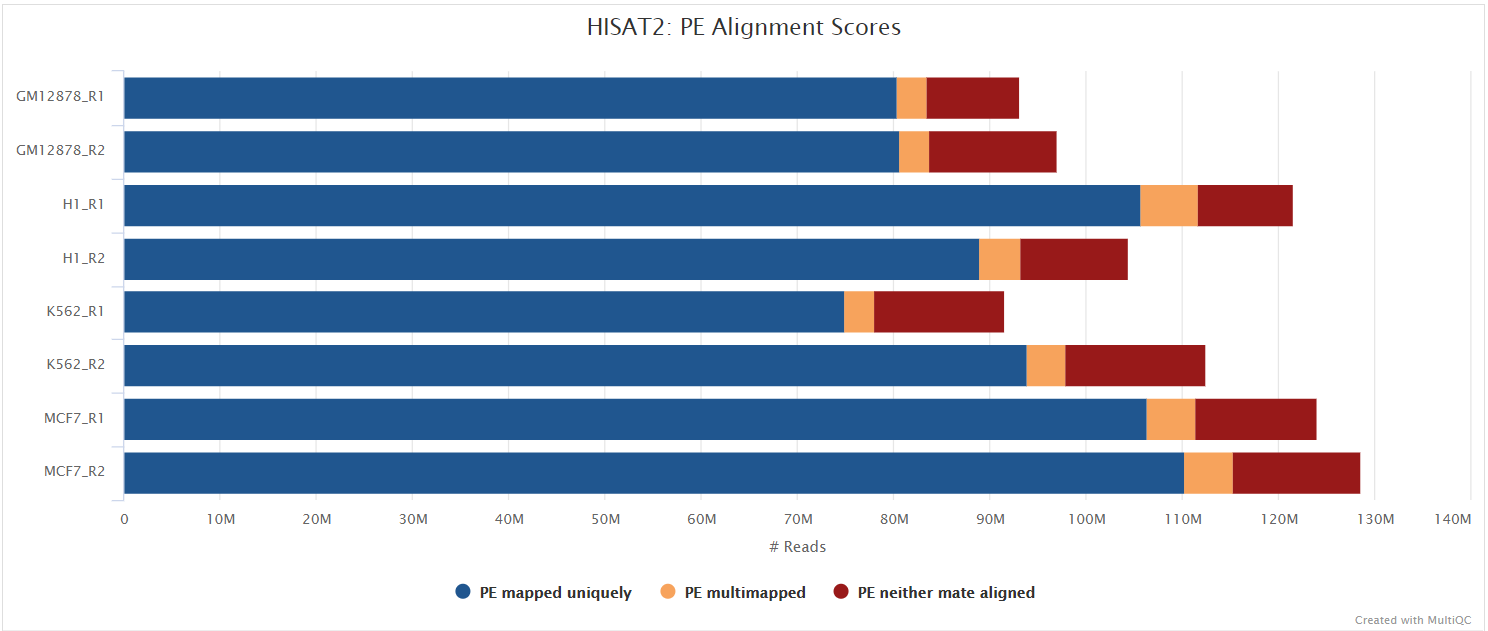
HISAT2
Output files
hisat2/<SAMPLE>.bam: If--save_align_intermedsis specified the original BAM file containing read alignments to the reference genome will be placed in this directory.
hisat2/log/*.log: HISAT2 alignment report containing the mapping results summary.
hisat2/unmapped/*.fastq.gz: If--save_unalignedis specified, FastQ files containing unmapped reads will be placed in this directory.
HISAT2 is a fast and sensitive alignment program for mapping next-generation sequencing reads (both DNA and RNA) to a population of human genomes as well as to a single reference genome. It introduced a new indexing scheme called a Hierarchical Graph FM index (HGFM) which when combined with several alignment strategies, enable rapid and accurate alignment of sequencing reads. The HISAT2 route through the pipeline is a good option if you have memory limitations on your compute. However, quantification isn’t performed if using --aligner hisat2 due to the lack of an appropriate option to calculate accurate expression estimates from HISAT2 derived genomic alignments. However, you can use this route if you have a preference for the alignment, QC and other types of downstream analysis compatible with the output of HISAT2.
You can choose to align your data with HISAT2 by providing the --aligner hisat2 parameter.
Alignment post-processing
The pipeline has been written in a way where all the files generated downstream of the alignment are placed in the same directory as specified by --aligner e.g. if --aligner star_salmon is specified then all the downstream results will be placed in the star_salmon/ directory. This helps with organising the directory structure and more importantly, allows the end-user to get the results from multiple aligners by simply re-running the pipeline with a different --aligner option along the -resume parameter. It also means that results won’t be overwritten when resuming the pipeline and can be used for benchmarking between alignment algorithms if required.
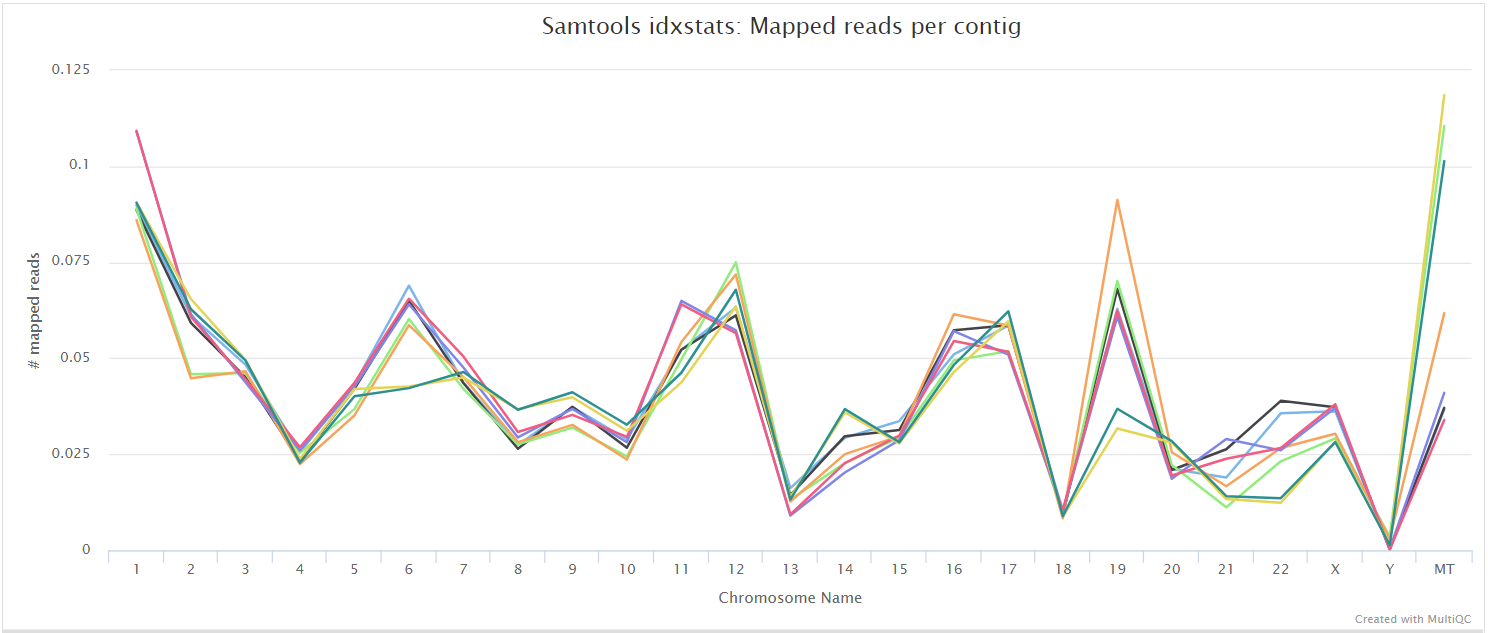
SAMtools
Output files
<ALIGNER>/<SAMPLE>.sorted.bam: If--save_align_intermedsis specified the original coordinate sorted BAM file containing read alignments will be placed in this directory.<SAMPLE>.sorted.bam.bai: If--save_align_intermedsis specified the BAI index file for the original coordinate sorted BAM file will be placed in this directory.<SAMPLE>.sorted.bam.csi: If--save_align_intermeds --bam_csi_indexis specified the CSI index file for the original coordinate sorted BAM file will be placed in this directory.
<ALIGNER>/samtools_stats/- SAMtools
<SAMPLE>.sorted.bam.flagstat,<SAMPLE>.sorted.bam.idxstatsand<SAMPLE>.sorted.bam.statsfiles generated from the alignment files.
- SAMtools
The original BAM files generated by the selected alignment algorithm are further processed with SAMtools to sort them by coordinate, for indexing, as well as to generate read mapping statistics.

UMI-tools dedup
Output files
<ALIGNER>/<SAMPLE>.umi_dedup.sorted.bam: If--save_umi_intermedsis specified the UMI deduplicated, coordinate sorted BAM file containing read alignments will be placed in this directory.<SAMPLE>.umi_dedup.sorted.bam.bai: If--save_umi_intermedsis specified the BAI index file for the UMI deduplicated, coordinate sorted BAM file will be placed in this directory.<SAMPLE>.umi_dedup.sorted.bam.csi: If--save_umi_intermeds --bam_csi_indexis specified the CSI index file for the UMI deduplicated, coordinate sorted BAM file will be placed in this directory.
<ALIGNER>/umitools/*_edit_distance.tsv: Reports the (binned) average edit distance between the UMIs at each position.*_per_umi.tsv: UMI-level summary statistics.*_per_umi_per_position.tsv: Tabulates the counts for unique combinations of UMI and position.
The content of the files above is explained in more detail in the UMI-tools documentation.
After extracting the UMI information from the read sequence (see UMI-tools extract), the second step in the removal of UMI barcodes involves deduplicating the reads based on both mapping and UMI barcode information using the UMI-tools dedup command. This will generate a filtered BAM file after the removal of PCR duplicates.
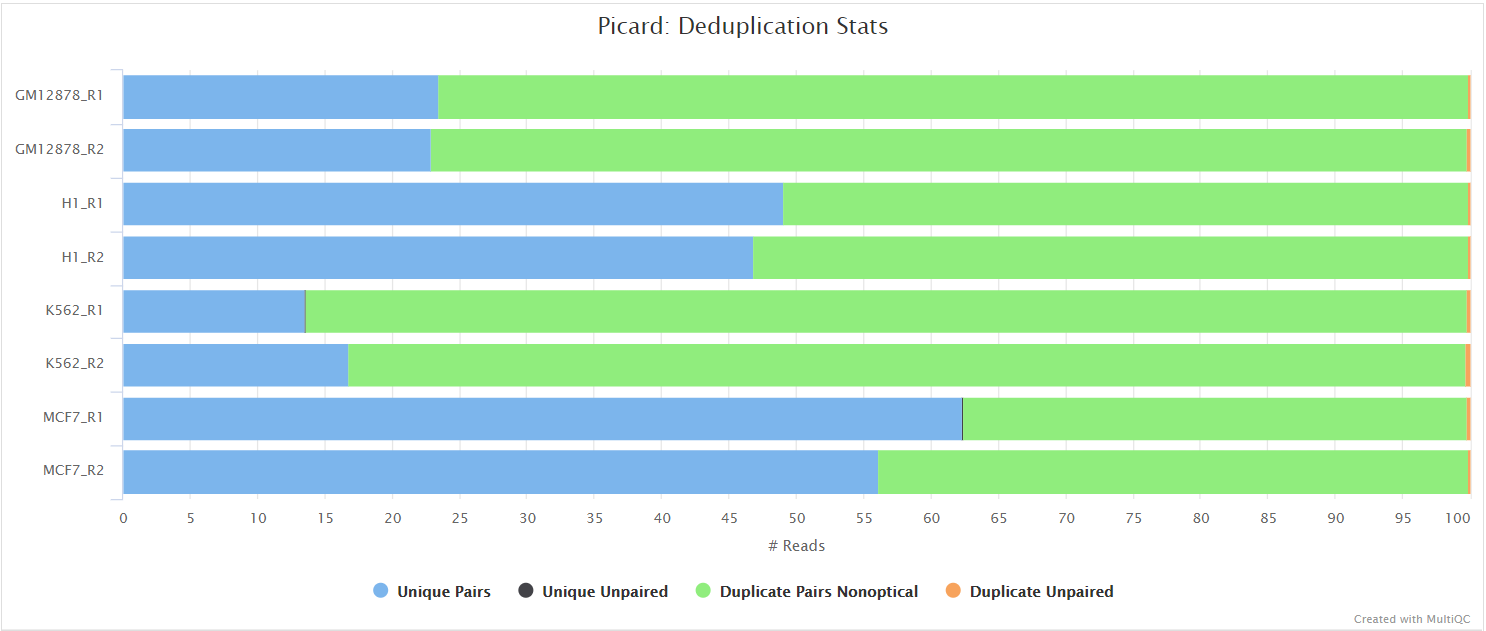
picard MarkDuplicates
Output files
<ALIGNER>/<SAMPLE>.markdup.sorted.bam: Coordinate sorted BAM file after duplicate marking. This is the final post-processed BAM file and so will be saved by default in the results directory.<SAMPLE>.markdup.sorted.bam.bai: BAI index file for coordinate sorted BAM file after duplicate marking. This is the final post-processed BAM index file and so will be saved by default in the results directory.<SAMPLE>.markdup.sorted.bam.csi: CSI index file for coordinate sorted BAM file after duplicate marking. This is the final post-processed BAM index file and so will be saved by default in the results directory. Only generated if--bam_csi_indexis specified as a parameter.
<ALIGNER>/samtools_stats/- SAMtools
<SAMPLE>.markdup.sorted.bam.flagstat,<SAMPLE>.markdup.sorted.bam.idxstatsand<SAMPLE>.markdup.sorted.bam.statsfiles generated from the duplicate marked alignment files.
- SAMtools
<ALIGNER>/picard_metrics/<SAMPLE>.markdup.sorted.MarkDuplicates.metrics.txt: Metrics file from MarkDuplicates.
Unless you are using UMIs it is not possible to establish whether the fragments you have sequenced from your sample were derived via true biological duplication (i.e. sequencing independent template fragments) or as a result of PCR biases introduced during the library preparation. By default, the pipeline uses picard MarkDuplicates to mark the duplicate reads identified amongst the alignments to allow you to guage the overall level of duplication in your samples. However, for RNA-seq data it is not recommended to physically remove duplicate reads from the alignments (unless you are using UMIs) because you expect a significant level of true biological duplication that arises from the same fragments being sequenced from for example highly expressed genes. You can skip this step via the --skip_markduplicates parameter.
Other steps
StringTie
Output files
<ALIGNER>/stringtie/*.coverage.gtf: GTF file containing transcripts that are fully covered by reads.*.transcripts.gtf: GTF file containing all of the assembled transcipts from StringTie.*.gene_abundance.txt: Text file containing gene aboundances and FPKM values.
<ALIGNER>/stringtie/<SAMPLE>.ballgown/: Ballgown output directory.
StringTie is a fast and highly efficient assembler of RNA-Seq alignments into potential transcripts. It uses a novel network flow algorithm as well as an optional de novo assembly step to assemble and quantitate full-length transcripts representing multiple splice variants for each gene locus. In order to identify differentially expressed genes between experiments, StringTie’s output can be processed by specialized software like Ballgown, Cuffdiff or other programs (DESeq2, edgeR, etc.).
BEDTools and bedGraphToBigWig
Output files
<ALIGNER>/bigwig/*.forward.bigWig: bigWig coverage file relative to genes on the forward DNA strand.*.reverse.bigWig: bigWig coverage file relative to genes on the reverse DNA strand.
The bigWig format is an indexed binary format useful for displaying dense, continuous data in Genome Browsers such as the UCSC and IGV. This mitigates the need to load the much larger BAM files for data visualisation purposes which will be slower and result in memory issues. The bigWig format is also supported by various bioinformatics software for downstream processing such as meta-profile plotting.
Quality control
RSeQC
RSeQC is a package of scripts designed to evaluate the quality of RNA-seq data. This pipeline runs several, but not all RSeQC scripts. You can tweak the supported scripts you would like to run by adjusting the --rseqc_modules parameter which by default will run all of the following: bam_stat.py, inner_distance.py, infer_experiment.py, junction_annotation.py, junction_saturation.py,read_distribution.py and read_duplication.py.
The majority of RSeQC scripts generate output files which can be plotted and summarised in the MultiQC report.
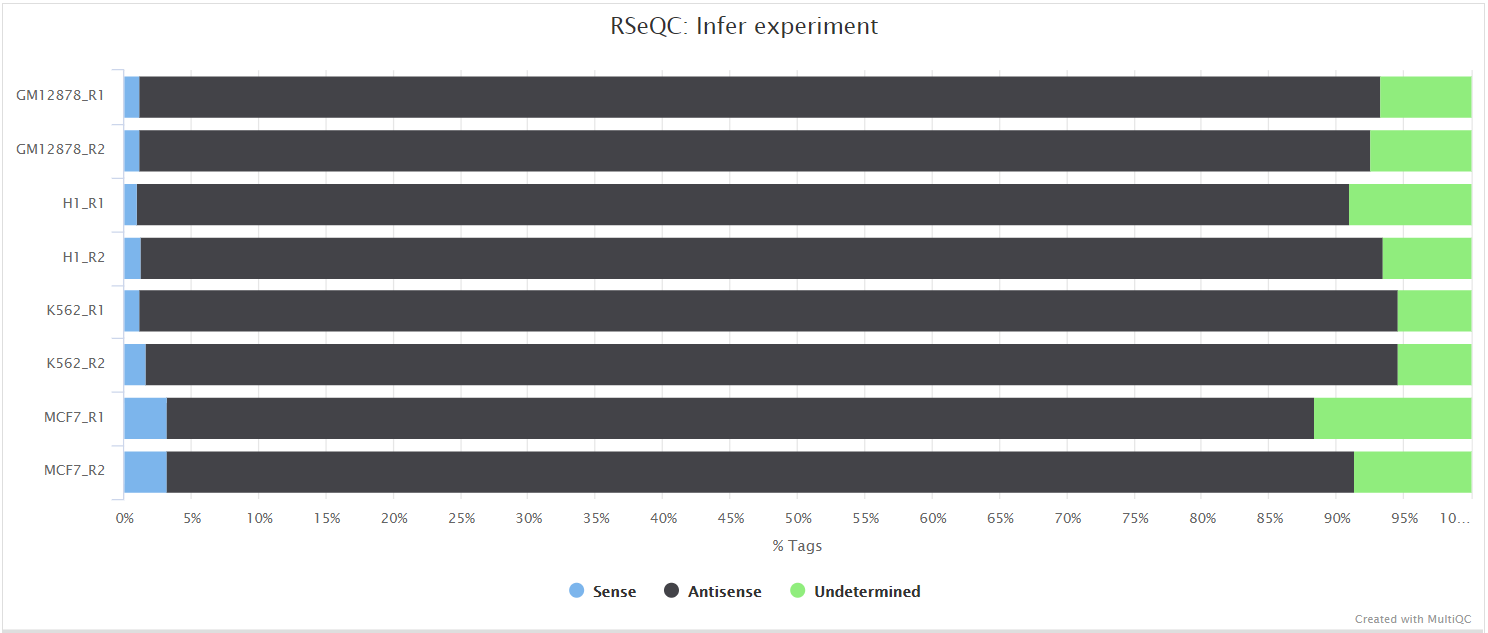
Infer experiment
Output files
<ALIGNER>/rseqc/infer_experiment/*.infer_experiment.txt: File containing fraction of reads mapping to given strandedness configurations.
This script predicts the “strandedness” of the protocol (i.e. unstranded, sense or antisense) that was used to prepare the sample for sequencing by assessing the orientation in which aligned reads overlay gene features in the reference genome. The strandedness of each sample has to be provided to the pipeline in the input samplesheet (see usage docs). However, this information is not always available, especially for public datasets. As a result, additional features have been incorporated into this pipeline to auto-detect whether you have provided the correct information in the samplesheet, and if this is not the case then a warning table will be placed at the top of the MultiQC report highlighting the offending samples (see image below). If required, this will allow you to correct the input samplesheet and rerun the pipeline with the accurate strand information. Note, it is important to get this information right because it can affect the final results.
RSeQC documentation: infer_experiment.py

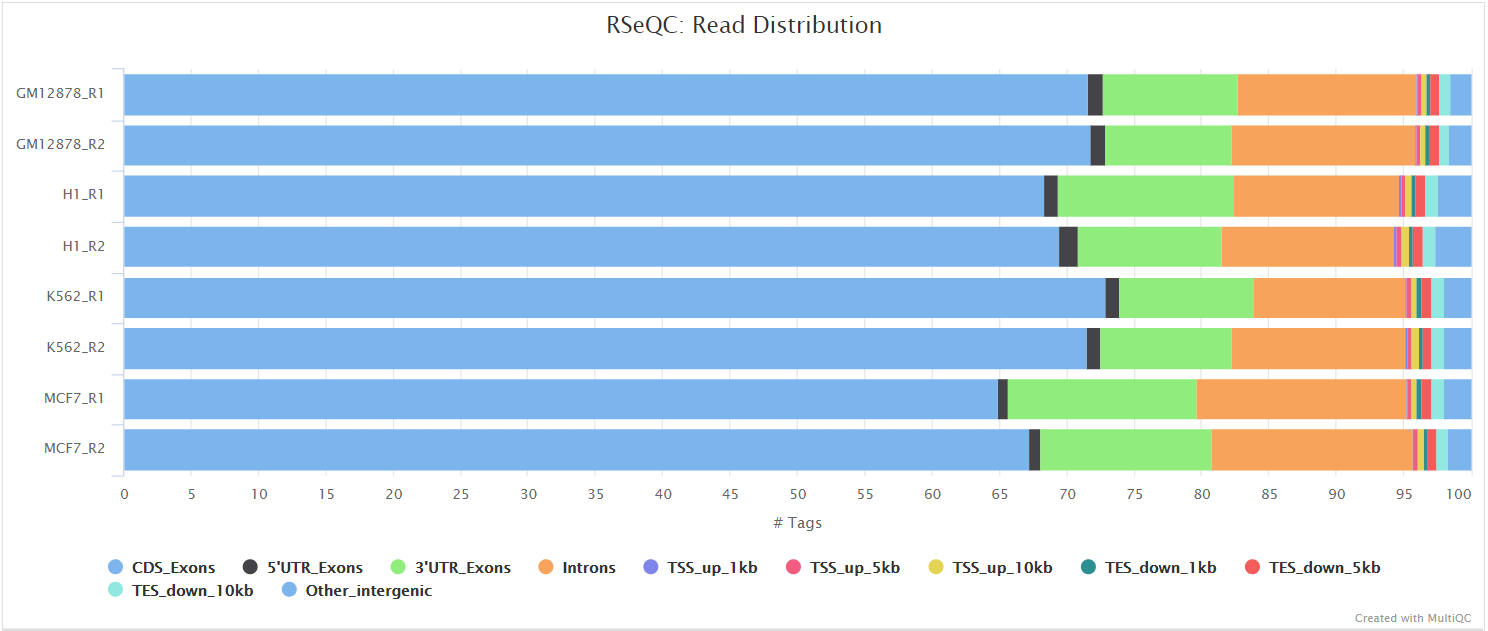
Read distribution
Output files
<ALIGNER>/rseqc/read_distribution/*.read_distribution.txt: File containing fraction of reads mapping to genome feature e.g. CDS exon, 5’UTR exon, 3’ UTR exon, Intron, Intergenic regions etc.
This tool calculates how mapped reads are distributed over genomic features. A good result for a standard RNA-seq experiments is generally to have as many exonic reads as possible (CDS_Exons). A large amount of intronic reads could be indicative of DNA contamination in your sample but may be expected for a total RNA preparation.
RSeQC documentation: read_distribution.py
Junction annotation
Output files
<ALIGNER>/rseqc/junction_annotation/bed/*.junction.bed: BED file containing splice junctions.*.junction.Interact.bed: BED file containing interacting splice junctions.
<ALIGNER>/rseqc/junction_annotation/log/*.junction_annotation.log: Log file generated by the program.
<ALIGNER>/rseqc/junction_annotation/pdf/*.splice_events.pdf: PDF file containing splicing events plot.*.splice_junction.pdf: PDF file containing splice junctions plot.
<ALIGNER>/rseqc/junction_annotation/rscript/*.junction_plot.r: R script used to generate pdf plots above.
<ALIGNER>/rseqc/junction_annotation/xls/*.junction.xls: Excel spreadsheet with junction information.
Junction annotation compares detected splice junctions to a reference gene model. Splicing annotation is performed in two levels: splice event level and splice junction level.
RSeQC documentation: junction_annotation.py
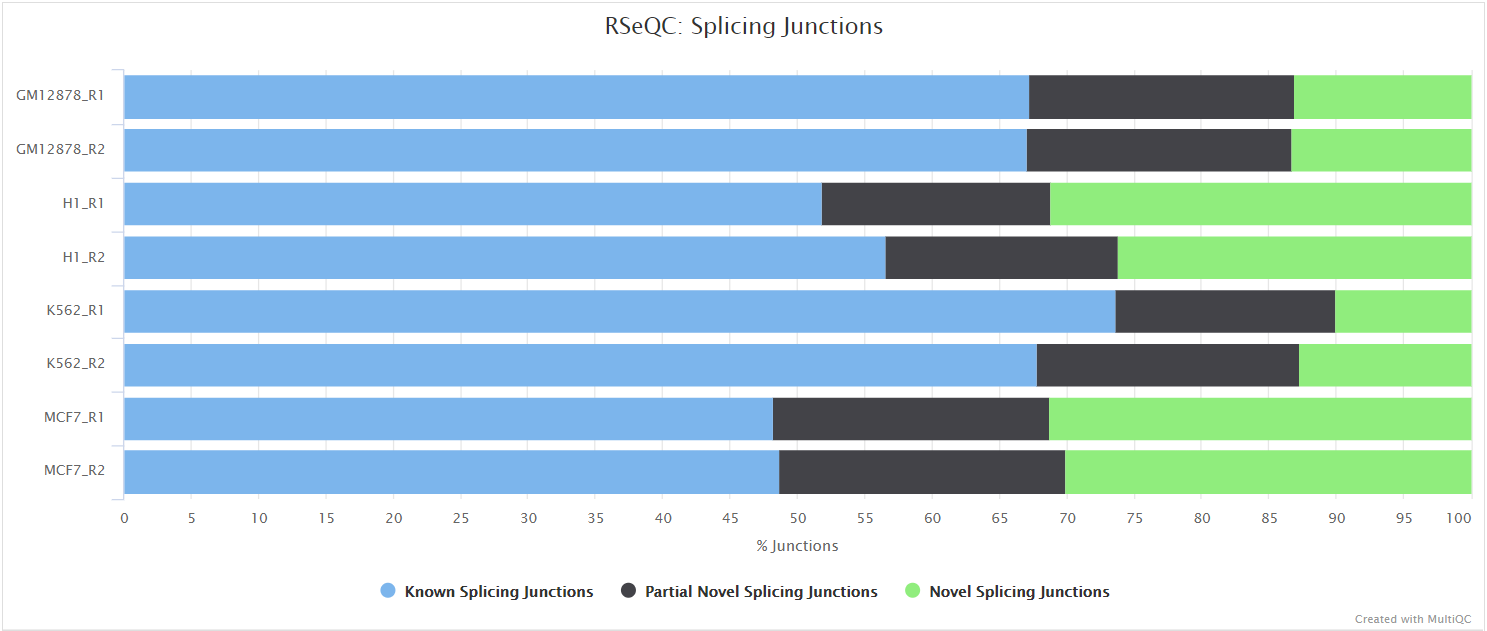
Inner distance
Output files
<ALIGNER>/rseqc/inner_distance/pdf/*.inner_distance_plot.pdf: PDF file containing inner distance plot.
<ALIGNER>/rseqc/inner_distance/rscript/*.inner_distance_plot.r: R script used to generate pdf plot above.
<ALIGNER>/rseqc/inner_distance/txt/*.inner_distance_freq.txt: File containing frequency of insert sizes.*.inner_distance_mean.txt: File containing mean, median and standard deviation of insert sizes.
The inner distance script tries to calculate the inner distance between two paired-end reads. It is the distance between the end of read 1 to the start of read 2, and it is sometimes confused with the insert size (see this blog post for disambiguation):
This plot will not be generated for single-end data. Very short inner distances are often seen in old or degraded samples (eg. FFPE) and values can be negative if the reads overlap consistently.
RSeQC documentation: inner_distance.py
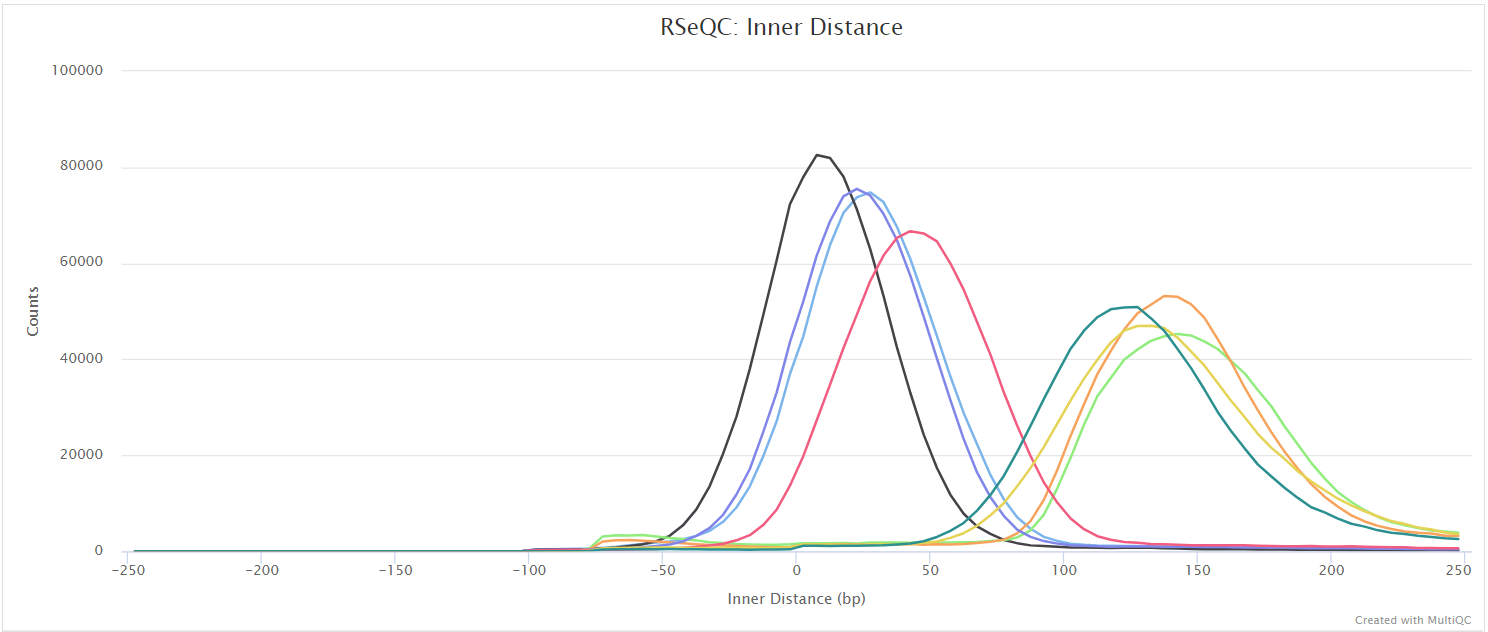
Junction saturation
Output files
<ALIGNER>/rseqc/junction_saturation/pdf/*.junctionSaturation_plot.pdf: PDF file containing junction saturation plot.
<ALIGNER>/rseqc/junction_saturation/rscript/*.junctionSaturation_plot.r: R script used to generate pdf plot above.
This script shows the number of splice sites detected within the data at various levels of subsampling. A sample that reaches a plateau before getting to 100% data indicates that all junctions in the library have been detected, and that further sequencing will not yield any more observations. A good sample should approach such a plateau of Known junctions, however, very deep sequencing is typically required to saturate all Novel Junctions in a sample.
RSeQC documentation: junction_saturation.py
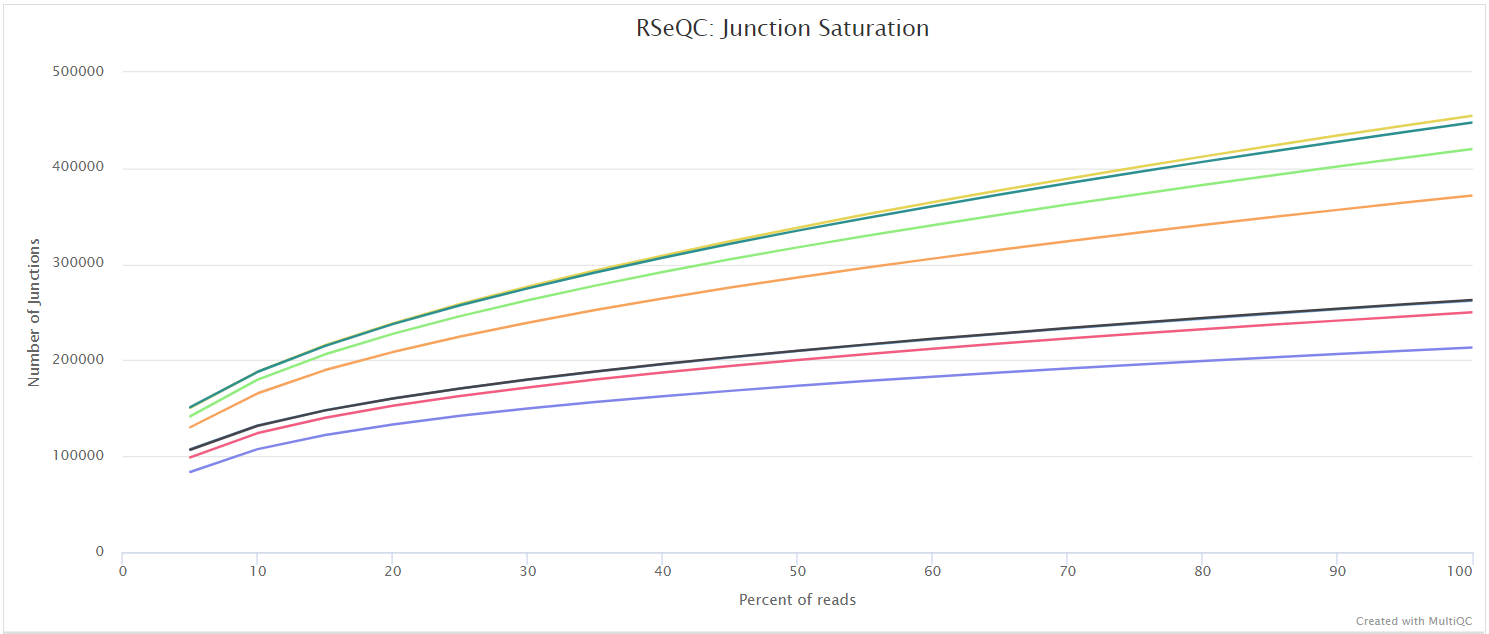
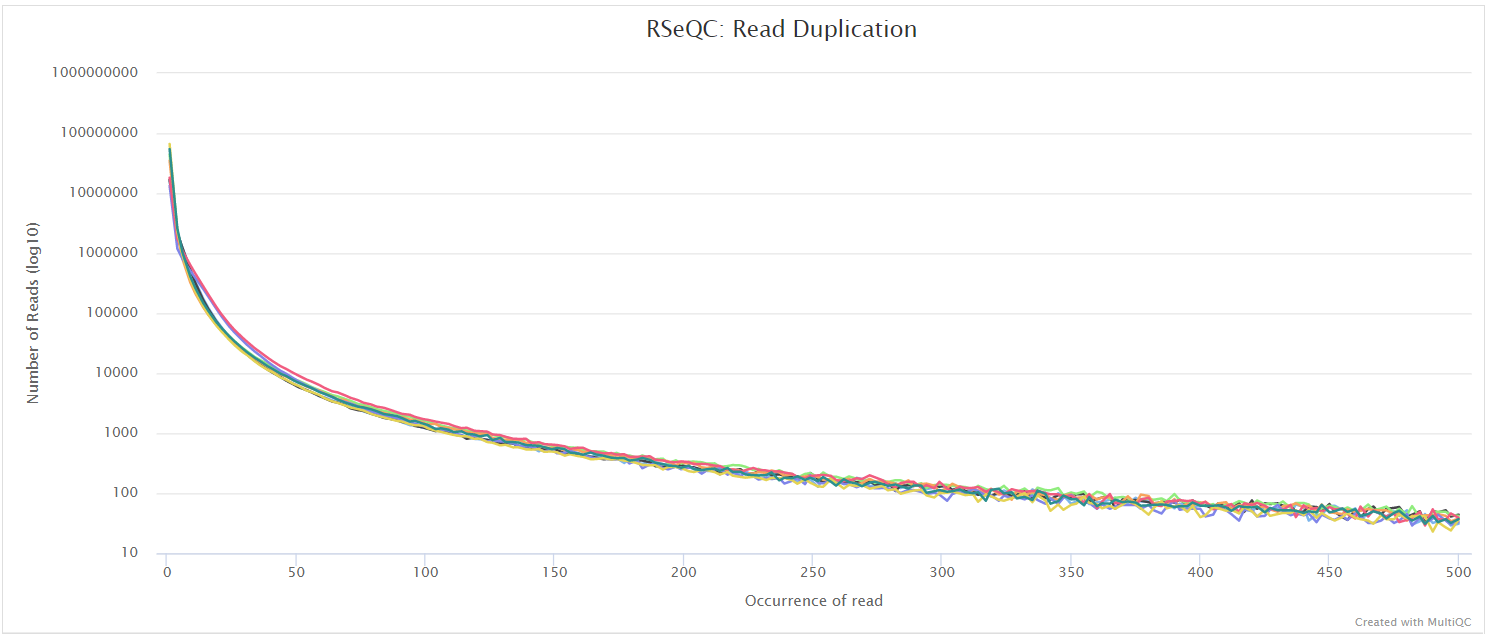
Read duplication
Output files
<ALIGNER>/rseqc/read_duplication/pdf/*.DupRate_plot.pdf: PDF file containing read duplication plot.
<ALIGNER>/rseqc/read_duplication/rscript/*.DupRate_plot.r: R script used to generate pdf plot above.
<ALIGNER>/rseqc/read_duplication/xls/*.pos.DupRate.xls: Read duplication rate determined from mapping position of read. First column is “occurrence” or duplication times, second column is number of uniquely mapped reads.*.seq.DupRate.xls: Read duplication rate determined from sequence of read. First column is “occurrence” or duplication times, second column is number of uniquely mapped reads.
This plot shows the number of reads (y-axis) with a given number of exact duplicates (x-axis). Most reads in an RNA-seq library should have a low number of exact duplicates. Samples which have many reads with many duplicates (a large area under the curve) may be suffering excessive technical duplication.
RSeQC documentation: read_duplication.py
BAM stat
Output files
<ALIGNER>/rseqc/bam_stat/*.bam_stat.txt: Mapping statistics for the BAM file.
This script gives numerous statistics about the aligned BAM files. A typical output looks as follows:
#Output (all numbers are read count)#==================================================Total records: 41465027QC failed: 0Optical/PCR duplicate: 0Non Primary Hits 8720455Unmapped reads: 0
mapq < mapq_cut (non-unique): 3127757mapq >= mapq_cut (unique): 29616815Read-1: 14841738Read-2: 14775077Reads map to '+': 14805391Reads map to '-': 14811424Non-splice reads: 25455360Splice reads: 4161455Reads mapped in proper pairs: 21856264Proper-paired reads map to different chrom: 7648MultiQC plots each of these statistics in a dot plot. Each sample in the project is a dot - hover to see the sample highlighted across all fields.
RSeQC documentation: bam_stat.py
TIN
Output files
<ALIGNER>/rseqc/tin/*.summary.txt: File containing TIN results summary.*.tin.xls: XLS file containing TIN results.
This script is designed to evaluate RNA integrity at the transcript level. TIN (transcript integrity number) is named in analogous to RIN (RNA integrity number). RIN (RNA integrity number) is the most widely used metric to evaluate RNA integrity at sample (or transcriptome) level. It is a very useful preventive measure to ensure good RNA quality and robust, reproducible RNA sequencing.
RSeQC documentation: tin.py
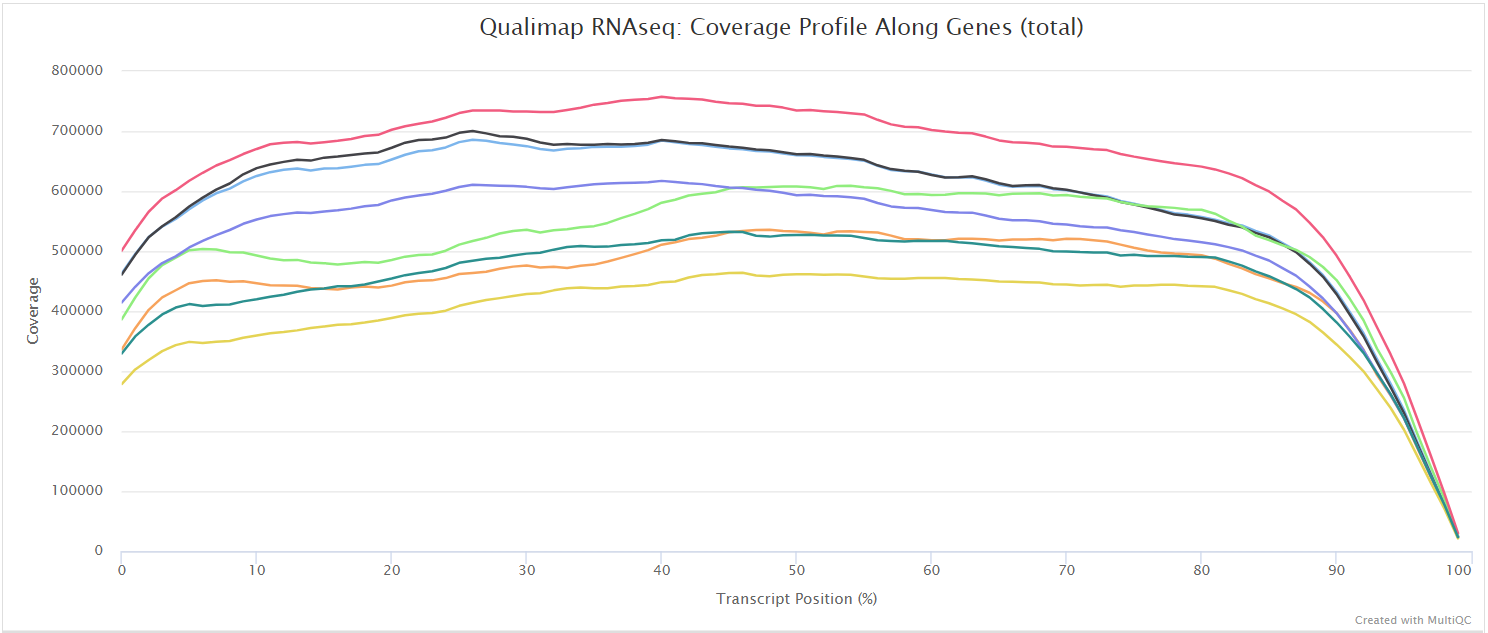
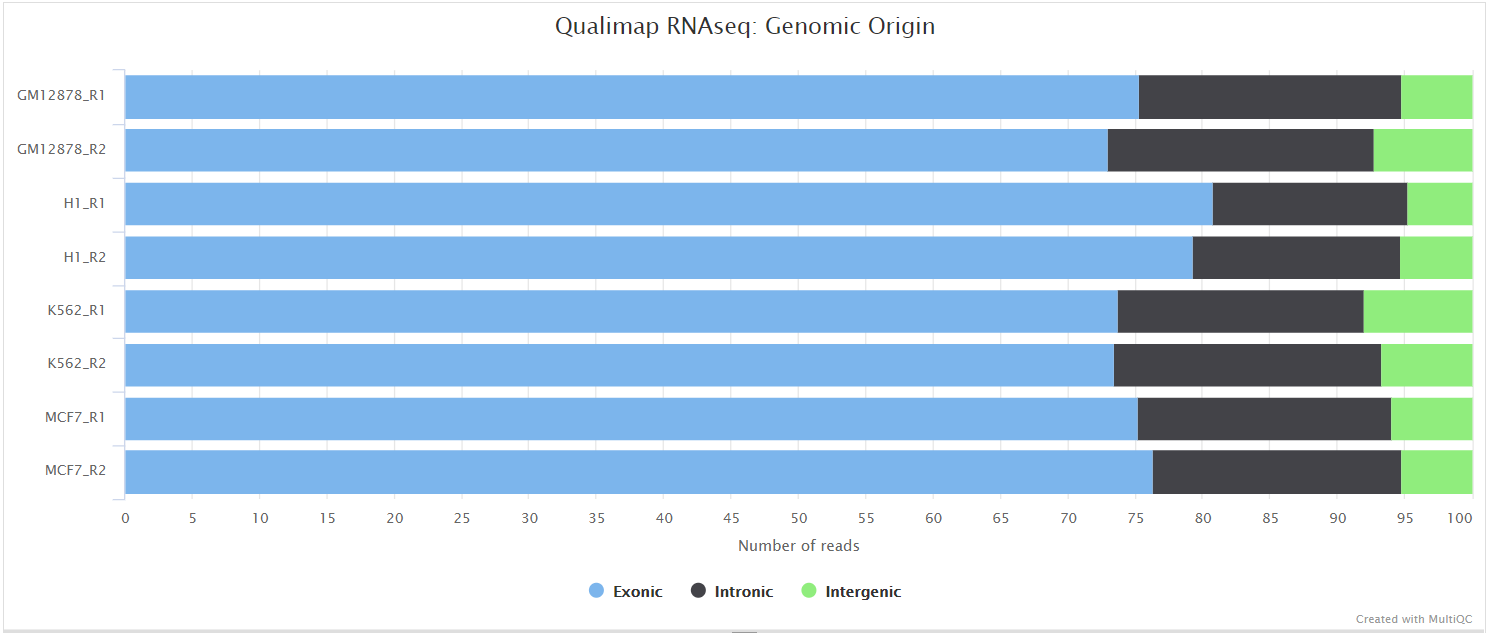
Qualimap
Output files
<ALIGNER>/qualimap/<SAMPLE>/qualimapReport.html: Qualimap HTML report that can be viewed in a web browser.rnaseq_qc_results.txt: Textual results output.
<ALIGNER>/qualimap/<SAMPLE>/images_qualimapReport/: Images required for the HTML report.<ALIGNER>/qualimap/<SAMPLE>/raw_data_qualimapReport/: Raw data required for the HTML report.<ALIGNER>/qualimap/<SAMPLE>/css/: CSS files required for the HTML report.
Qualimap is a platform-independent application written in Java and R that provides both a Graphical User Interface (GUI) and a command-line interface to facilitate the quality control of alignment sequencing data. Shortly, Qualimap:
- Examines sequencing alignment data according to the features of the mapped reads and their genomic properties.
- Provides an overall view of the data that helps to to the detect biases in the sequencing and/or mapping of the data and eases decision-making for further analysis.
The Qualimap RNA-seq QC module is used within this pipeline to assess the overall mapping and coverage relative to gene features.
dupRadar
Output files
<ALIGNER>/dupradar/box_plot/*_duprateExpBoxplot.pdf: PDF file containing box plot for duplicate rate relative to mean expression.
<ALIGNER>/dupradar/gene_data/*_dupMatrix.txt: Text file containing duplicate metrics per gene.
<ALIGNER>/dupradar/histogram/*_expressionHist.pdf: PDF file containing histogram of reads per kilobase values per gene.
<ALIGNER>/dupradar/intercepts_slope/*_intercept_slope.txt: Text file containing intercept slope values.
<ALIGNER>/dupradar/scatter_plot/*_duprateExpDens.pdf: PDF file containing typical dupRadar 2D density scatter plot.
See dupRadar docs for further information regarding the content of these files.
dupRadar is a Bioconductor library written in the R programming language. It generates various QC metrics and plots that relate duplication rate with gene expression levels in order to identify experiments with high technical duplication. A good sample with little technical duplication will only show high numbers of duplicates for highly expressed genes. Samples with technical duplication will have high duplication for all genes, irrespective of transcription level.
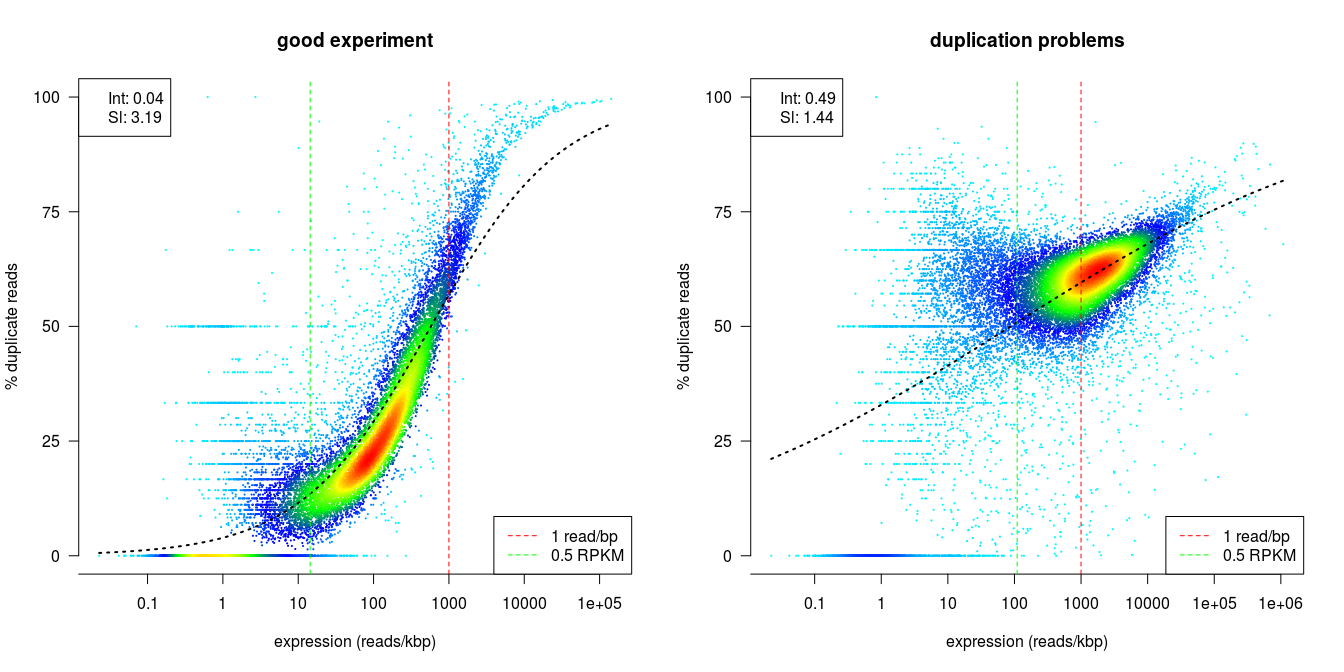
Credit: dupRadar documentation
Preseq
Output files
<ALIGNER>/preseq/*.ccurve.txt: Preseq expected future yield file.
<ALIGNER>/preseq/log/*.command.log: Standard error output from command.
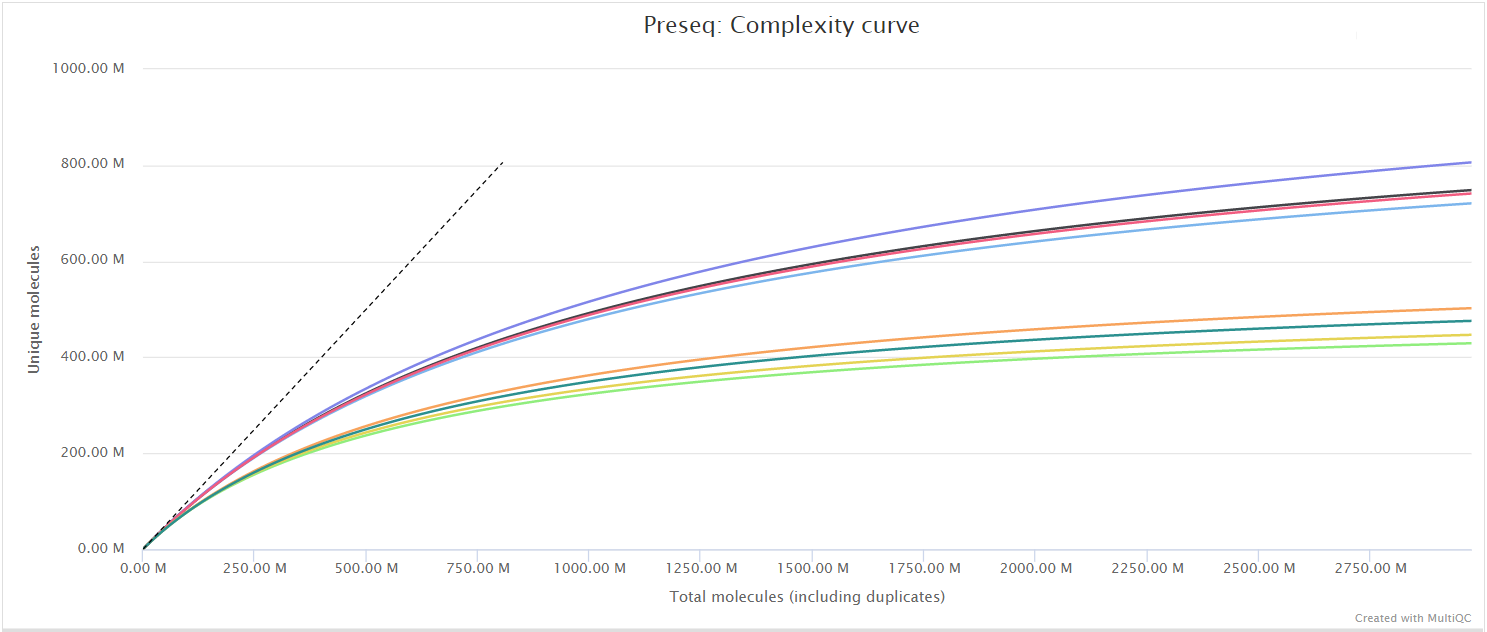
The Preseq package is aimed at predicting and estimating the complexity of a genomic sequencing library, equivalent to predicting and estimating the number of redundant reads from a given sequencing depth and how many will be expected from additional sequencing using an initial sequencing experiment. The estimates can then be used to examine the utility of further sequencing, optimize the sequencing depth, or to screen multiple libraries to avoid low complexity samples. A shallow curve indicates that the library has reached complexity saturation and further sequencing would likely not add further unique reads. The dashed line shows a perfectly complex library where total reads = unique reads. Note that these are predictive numbers only, not absolute. The MultiQC plot can sometimes give extreme sequencing depth on the X axis - click and drag from the left side of the plot to zoom in on more realistic numbers.
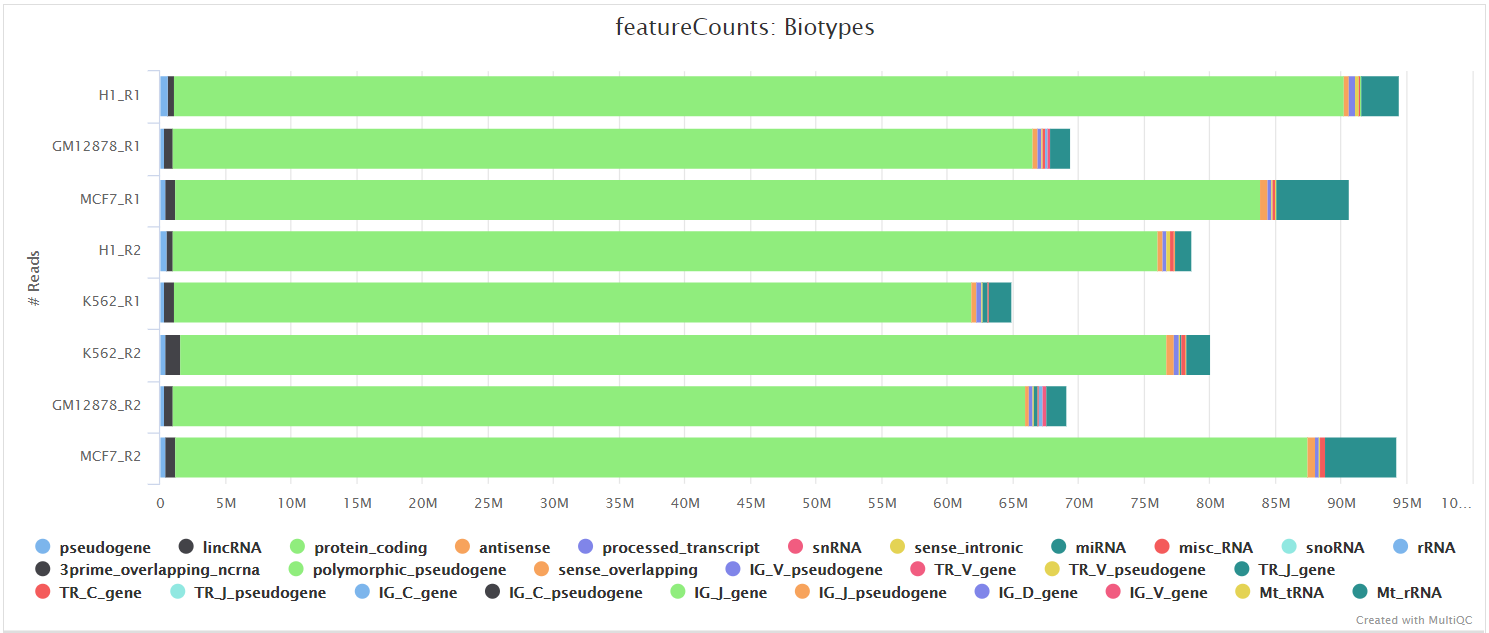
featureCounts
Output files
<ALIGNER>/featurecounts/*.featureCounts.txt: featureCounts biotype-level quantification results for each sample.*.featureCounts.txt.summary: featureCounts summary file containing overall statistics about the counts.*_mqc.tsv: MultiQC custom content files used to plot biotypes in report.
featureCounts from the Subread package is a quantification tool used to summarise the mapped read distribution over genomic features such as genes, exons, promotors, gene bodies, genomic bins and chromosomal locations. We can also use featureCounts to count overlaps with different classes of genomic features. This provides an additional QC to check which features are most abundant in the sample, and to highlight potential problems such as rRNA contamination.
DESeq2
Output files
<ALIGNER/PSEUDOALIGNER>/deseq2_qc/*.plots.pdf: File containing PCA and hierarchical clustering plots.*.dds.RData: File containing RDESeqDataSetobject generated by DESeq2, with either an rlog or vstassaystoring the variance-stabilised data.*.rds: Alternative version of the RData file suitable forreadRDSto give user control of the eventual object name.*pca.vals.txt: Matrix of values for the first 2 principal components.*sample.dists.txt: Sample distance matrix.R_sessionInfo.log: File containing information about R, the OS and attached or loaded packages.
<ALIGNER/PSEUDOALIGNER>/deseq2_qc/size_factors/*.txt,*.RData: Files containing DESeq2 sizeFactors per sample.
DESeq2 is one of the most commonly used software packages to perform differential expression analysis for RNA-seq datasets.
This pipeline uses a standardised DESeq2 analysis script to get an idea of the reproducibility across samples within the experiment. Please note that this will not suit every experimental design, and if there are other problems with the experiment then it may not work as well as expected.
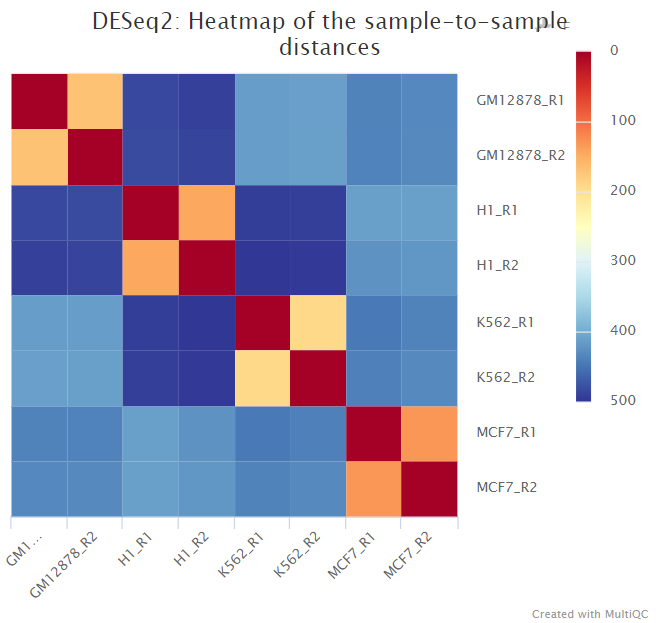
The script included in the pipeline uses DESeq2 to normalise read counts across all of the provided samples in order to create a PCA plot and a clustered heatmap showing pairwise Euclidean distances between the samples in the experiment. These help to show the similarity between groups of samples and can reveal batch effects and other potential issues with the experiment.
For larger experiments, it may be recommended to use the vst transformation instead of the default rlog option. You can do this by providing the --deseq2_vst parameter to the pipeline. See DESeq2 docs for a more detailed explanation.
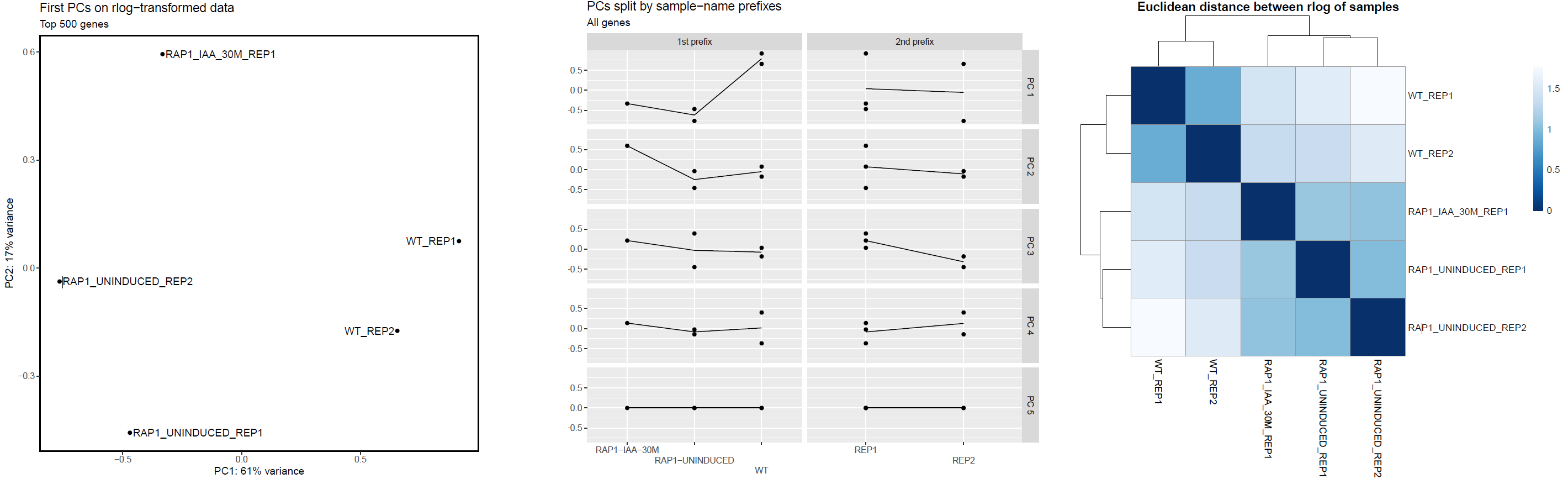
The PCA plots are generated based alternately on the top five hundred most variable genes, or all genes. The former is the conventional approach that is more likely to pick up strong effects (ie the biological signal) and the latter, when different, is picking up a weaker but consistent effect that is synchronised across many transcripts. We project both of these onto the first two PCs (shown in the top row of the figure below), which is the best two dimensional representation of the variation between samples.
We also explore higher components in terms of experimental factors inferred from sample names. If your sample naming convention follows a strict policy of using underscores to delimit values of experimental factors (for example WT_UNTREATED_REP1) and all names have the same number of underscores (so excluding WT_TREATED_10ml_REP1 from being compatible with the previous label), then any of these factors that are informative (ie label some but not all samples the same) then we individually plot upto the first five PCs, per experimental level, for each of the experimental factors.
The plot on the left hand side shows the standard PC plot - notice the variable number of underscores, meaning that the central plot would not be produced: here we have changed the underscore that is hyphenating the treatment to a ‘-’ character. This allows the central plot to be generated, and we can see that replicate (the 2nd part of the sample name) seems to be affecting the 3rd principal component, but the treatment factor is affecting the more important first two components. The right-most plot shows all pairwise euclidean distances between the samples.
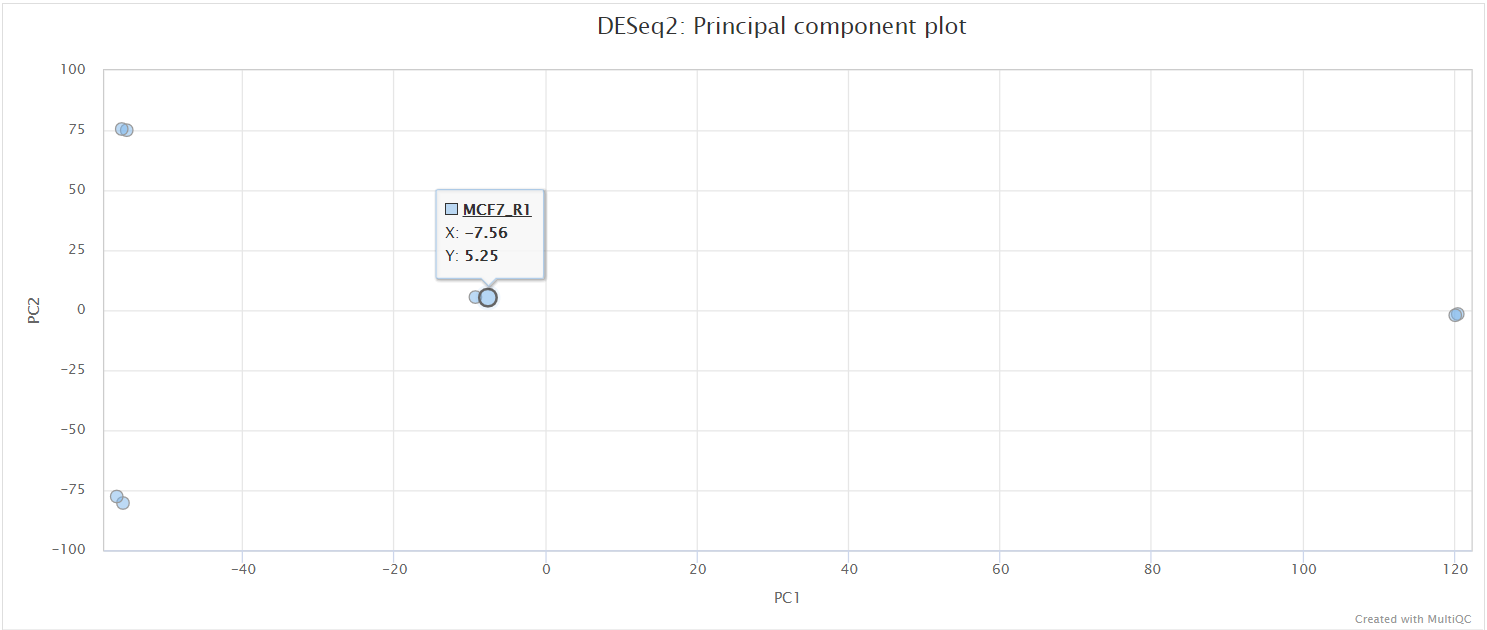
MultiQC
Output files
multiqc/<ALIGNER>/multiqc_report.html: a standalone HTML file that can be viewed in your web browser.multiqc_data/: directory containing parsed statistics from the different tools used in the pipeline.
MultiQC is a visualization tool that generates a single HTML report summarising all samples in your project. Most of the pipeline QC results are visualised in the report and further statistics are available in the report data directory.
Results generated by MultiQC collate pipeline QC from supported tools i.e. FastQC, Cutadapt, SortMeRNA, STAR, RSEM, HISAT2, Salmon, SAMtools, Picard, RSeQC, Qualimap, Preseq and featureCounts. Additionally, various custom content has been added to the report to assess the output of dupRadar, DESeq2 and featureCounts biotypes, and to highlight samples failing a mimimum mapping threshold or those that failed to match the strand-specificity provided in the input samplesheet. The pipeline has special steps which also allow the software versions to be reported in the MultiQC output for future traceability. For more information about how to use MultiQC reports, see http://multiqc.info.
Pseudo-alignment and quantification
Salmon
Output files
salmon/salmon.merged.gene_counts.tsv: Matrix of gene-level raw counts across all samples.salmon.merged.gene_tpm.tsv: Matrix of gene-level TPM values across all samples.salmon.merged.gene_counts.rds: RDS object that can be loaded in R that contains a SummarizedExperiment container with the TPM (abundance), estimated counts (counts) and transcript length (length) in the assays slot for genes.salmon.merged.gene_counts_scaled.tsv: Matrix of gene-level scaled counts across all samples.salmon.merged.gene_counts_scaled.rds: RDS object that can be loaded in R that contains a SummarizedExperiment container with the TPM (abundance), estimated counts (counts) and transcript length (length) in the assays slot for genes.salmon.merged.gene_counts_length_scaled.tsv: Matrix of gene-level length-scaled counts across all samples.salmon.merged.gene_counts_length_scaled.rds: RDS object that can be loaded in R that contains a SummarizedExperiment container with the TPM (abundance), estimated counts (counts) and transcript length (length) in the assays slot for genes.salmon.merged.transcript_counts.tsv: Matrix of isoform-level raw counts across all samples.salmon.merged.transcript_tpm.tsv: Matrix of isoform-level TPM values across all samples.salmon.merged.transcript_counts.rds: RDS object that can be loaded in R that contains a SummarizedExperiment container with the TPM (abundance), estimated counts (counts) and transcript length (length) in the assays slot for transcripts.salmon_tx2gene.tsv: Tab-delimited file containing gene to transcripts ids mappings.
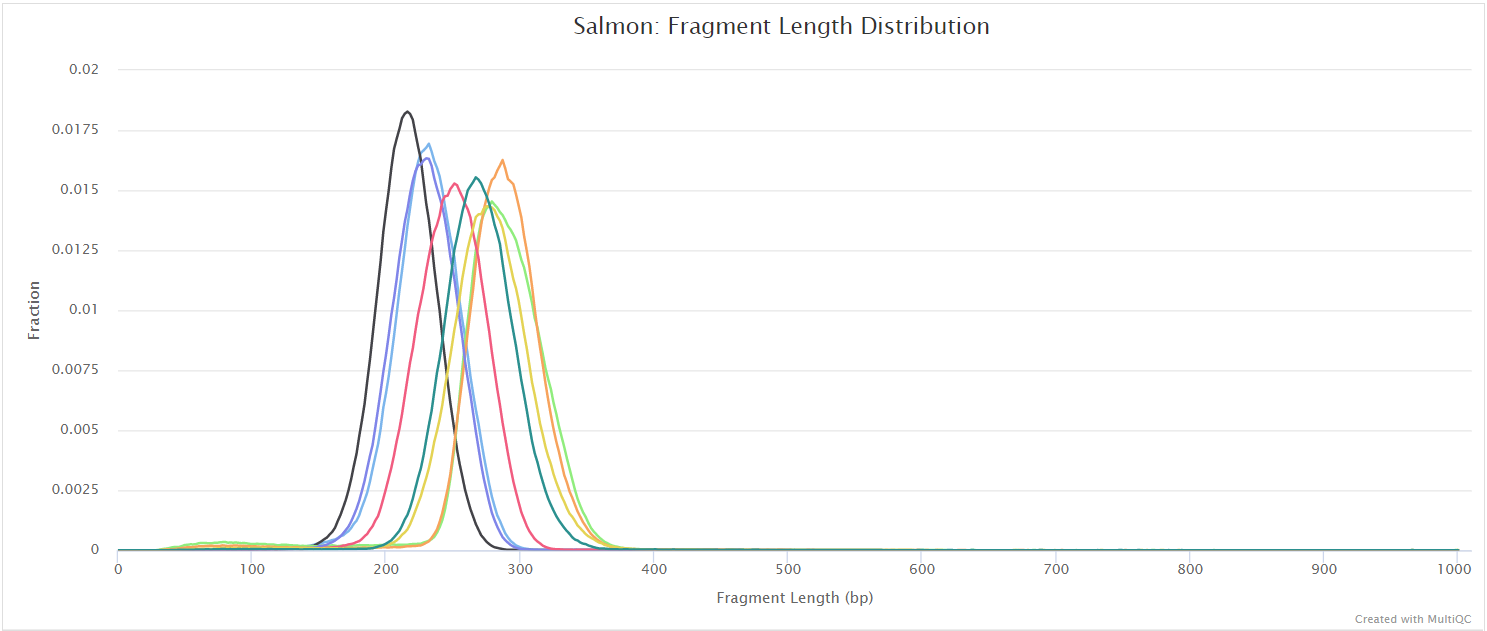
salmon/<SAMPLE>/aux_info/: Auxiliary info e.g. versions and number of mapped reads.cmd_info.json: Information about the Salmon quantification command, version and options.lib_format_counts.json: Number of fragments assigned, unassigned and incompatible.libParams/: Contains the fileflenDist.txtfor the fragment length distribution.logs/: Contains the filesalmon_quant.loggiving a record of Salmon’s quantification.quant.genes.sf: Salmon gene-level quantification of the sample, including feature length, effective length, TPM, and number of reads.quant.sf: Salmon transcript-level quantification of the sample, including feature length, effective length, TPM, and number of reads.
As described in the STAR and Salmon section, you can choose to pseudo-align and quantify your data with Salmon by providing the --pseudo_aligner salmon parameter. By default, Salmon is run in addition to the standard alignment workflow defined by --aligner, mainly because it allows you to obtain QC metrics with respect to the genomic alignments. However, you can provide the --skip_alignment parameter if you would like to run Salmon in isolation.
Transcripts with large inferential uncertainty won’t be assigned the exact number of reads reproducibly, every time Salmon is run. Read more about this on the nf-core/rnaseq and salmon Github repos.
The tximport package is used in this pipeline to summarise the results generated by Salmon into matrices for use with downstream differential analysis packages. We use tximport with different options to summarize count and TPM quantifications at the gene- and transcript-level. Please see #499 for discussion and links regarding which counts are suitable for different types of analysis.
According to the txtimport documentation you can do one of the following:
- Use bias corrected counts with an offset: import all the salmon files with
tximportand then useDESeq2withdds <- DESeqDataSetFromTximport(txi, sampleTable, ~condition)to correct for changes to the average transcript length across samples. - Use bias corrected counts without an offset: load and use
salmon.merged.gene_counts_length_scaled.tsvorsalmon.merged.gene_counts_scaled.tsvdirectly as you would with a regular counts matrix. - Use bias uncorrected counts: load and use the
txi$countsmatrix (orsalmon.merged.gene_counts.tsv) withDESeq2. This does not correct for potential differential isoform usage. Alternatively, if you have 3’ tagged RNA-seq data this is the most suitable method.
NB: The default Salmon parameters and a k-mer size of 31 are used to create the index. As documented here and discussed here, a k-mer size off 31 works well with reads that are 75bp or longer.
Workflow reporting and genomes
Reference genome files
Output files
genome/*.fa,*.gtf,*.gff,*.bed,.tsv: If the--save_referenceparameter is provided then all of the genome reference files will be placed in this directory.
genome/index/star/: Directory containing STAR indices.hisat2/: Directory containing HISAT2 indices.rsem/: Directory containing STAR and RSEM indices.salmon/: Directory containing Salmon indices.
A number of genome-specific files are generated by the pipeline because they are required for the downstream processing of the results. If the --save_reference parameter is provided then these will be saved in the genome/ directory. It is recommended to use the --save_reference parameter if you are using the pipeline to build new indices so that you can save them somewhere locally. The index building step can be quite a time-consuming process and it permits their reuse for future runs of the pipeline to save disk space.
Pipeline information
Output files
pipeline_info/- Reports generated by Nextflow:
execution_report.html,execution_timeline.html,execution_trace.txtandpipeline_dag.dot/pipeline_dag.svg. - Reports generated by the pipeline:
pipeline_report.html,pipeline_report.txtandsoftware_versions.yml. Thepipeline_report*files will only be present if the--email/--email_on_failparameter’s are used when running the pipeline. - Reformatted samplesheet files used as input to the pipeline:
samplesheet.valid.csv.
- Reports generated by Nextflow:
Nextflow provides excellent functionality for generating various reports relevant to the running and execution of the pipeline. This will allow you to troubleshoot errors with the running of the pipeline, and also provide you with other information such as launch commands, run times and resource usage.