nf-core/taxprofiler
Highly parallelised multi-taxonomic profiling of shotgun short- and long-read metagenomic data
1.1.4). The latest
stable release is
1.2.6
.
Introduction
nf-core/taxprofiler is a bioinformatics best-practice analysis pipeline for taxonomic classification and profiling of shotgun short- and long-read metagenomic data. It allows for in-parallel taxonomic identification of reads or taxonomic abundance estimation with multiple classification and profiling tools against multiple databases, and produces standardised output tables for facilitating results comparison between different tools and databases.
Pipeline summary
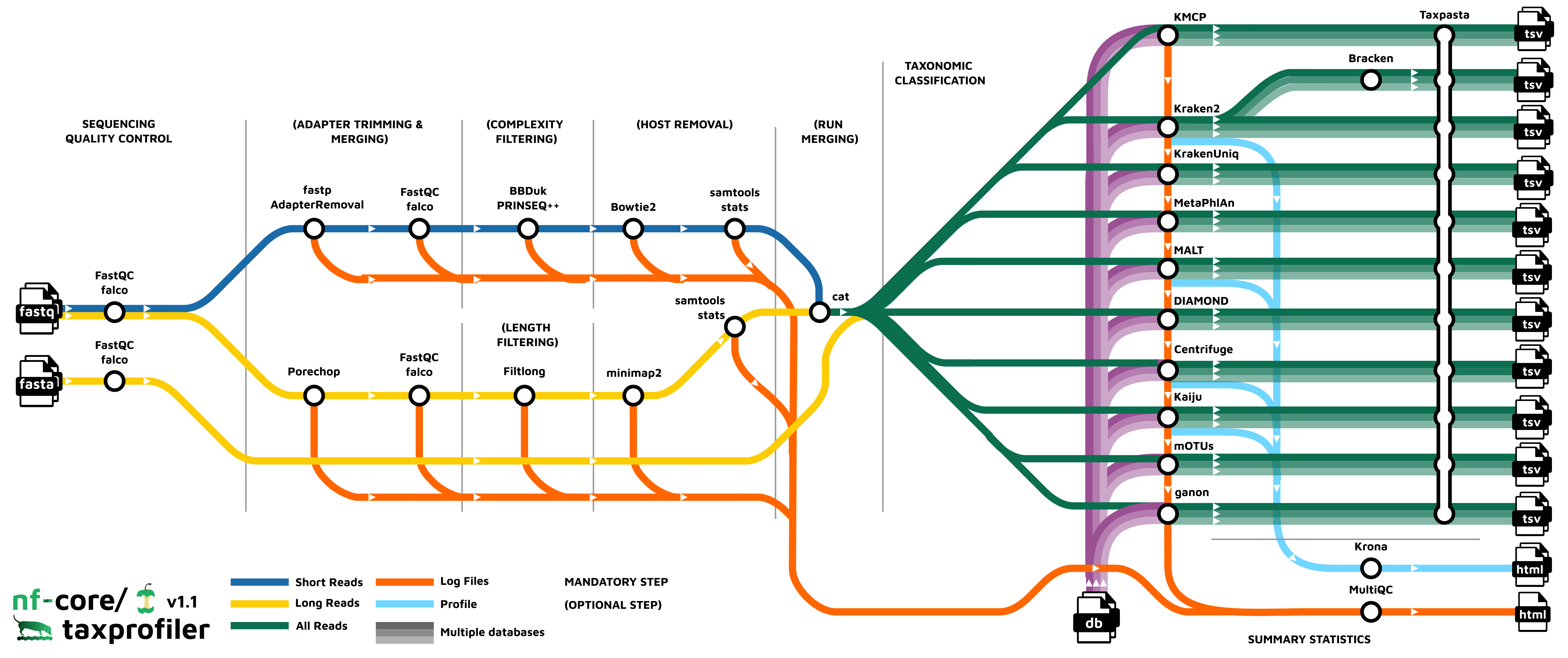
- Read QC (
FastQCorfalcoas an alternative option) - Performs optional read pre-processing
- Supports statistics for host-read removal (Samtools)
- Performs taxonomic classification and/or profiling using one or more of:
- Perform optional post-processing with:
- Standardises output tables (
Taxpasta) - Present QC for raw reads (
MultiQC) - Plotting Kraken2, Centrifuge, Kaiju and MALT results (
Krona)
Usage
If you are new to Nextflow and nf-core, please refer to this page on how to set-up Nextflow. Make sure to test your setup with -profile test before running the workflow on actual data.
First, prepare a samplesheet with your input data that looks as follows:
samplesheet.csv:
sample,run_accession,instrument_platform,fastq_1,fastq_2,fasta
2612,run1,ILLUMINA,2612_run1_R1.fq.gz,,
2612,run2,ILLUMINA,2612_run2_R1.fq.gz,,
2612,run3,ILLUMINA,2612_run3_R1.fq.gz,2612_run3_R2.fq.gz,Each row represents a fastq file (single-end), a pair of fastq files (paired end), or a fasta (with long reads).
Additionally, you will need a database sheet that looks as follows:
databases.csv:
tool,db_name,db_params,db_path
kraken2,db2,--quick,/<path>/<to>/kraken2/testdb-kraken2.tar.gz
metaphlan,db1,,/<path>/<to>/metaphlan/metaphlan_database/That includes directories or .tar.gz archives containing databases for the tools you wish to run the pipeline against.
Now, you can run the pipeline using:
nextflow run nf-core/taxprofiler \
-profile <docker/singularity/.../institute> \
--input samplesheet.csv \
--databases databases.csv \
--outdir <OUTDIR> \
--run_kraken2 --run_metaphlanPlease provide pipeline parameters via the CLI or Nextflow -params-file option. Custom config files including those provided by the -c Nextflow option can be used to provide any configuration except for parameters;
see docs.
For more details and further functionality, please refer to the usage documentation and the parameter documentation.
Pipeline output
To see the results of an example test run with a full size dataset refer to the results tab on the nf-core website pipeline page. For more details about the output files and reports, please refer to the output documentation.
Credits
nf-core/taxprofiler was originally written by James A. Fellows Yates, Sofia Stamouli, Moritz E. Beber, and the nf-core/taxprofiler team.
Team
We thank the following people for their contributions to the development of this pipeline:
- Lauri Mesilaakso
- Tanja Normark
- Maxime Borry
- Thomas A. Christensen II
- Jianhong Ou
- Rafal Stepien
- Mahwash Jamy
- Lily Andersson Lee
Acknowledgments
We also are grateful for the feedback and comments from:
- The general nf-core/community
And specifically to
❤️ also goes to Zandra Fagernäs for the logo.
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don’t hesitate to get in touch on the Slack #taxprofiler channel (you can join with this invite).
Citations
If you use nf-core/taxprofiler for your analysis, please cite it using the following doi: 10.1101/2023.10.20.563221.
Stamouli, S., Beber, M. E., Normark, T., Christensen II, T. A., Andersson-Li, L., Borry, M., Jamy, M., nf-core community, & Fellows Yates, J. A. (2023). nf-core/taxprofiler: Highly parallelised and flexible pipeline for metagenomic taxonomic classification and profiling. In bioRxiv (p. 2023.10.20.563221). https://doi.org/10.1101/2023.10.20.563221
For the latest version of the code, cite the Zenodo doi: 10.5281/zenodo.7728364
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md file.
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.