Regulatory aspects for nf-core pipelines
nf-core aims to produce high-quality Nextflow pipelines that facilitate validation and regulatory compliance through a comprehensive metrics-based approach. The community is organized around the regulatory special interest group, where stakeholders collaborate to define and implement validation standards.
Document version
2.0.0 draft
nf-core validation strategy
nf-core has developed a systematic approach to pipeline validation that balances community-driven quality assurance with institutional flexibility:
Our approach
- Metrics collection: nf-core automatically collects and maintains comprehensive quality metrics for all pipelines through the nf-core/stats service
- Validation readiness reports: Each pipeline release includes an automated PDF report containing validation-relevant metrics and quality indicators
- Community standards: The nf-core community maintains consistent quality standards across all pipelines through established guidelines and testing frameworks
- User flexibility: Institutions use nf-core reports as a foundation for their own validation processes, tailored to specific regulatory requirements and infrastructure
What nf-core provides
- Comprehensive metrics collection via nf-core/stats
- Automated validation readiness reports with each pipeline release
- Quality assurance frameworks (testing, documentation, versioning)
- Implementation guidance for institutional validation
- Continuous improvement through gap identification and community feedback
What users are responsible for
- Institution-specific validation within their target environment
- Regulatory compliance according to applicable standards
- Infrastructure validation (CSV and system-level requirements, aka IQ/PQ/OQ)
- Risk assessment for their specific use cases
- Ongoing maintenance and re-validation as needed
nf-core provides the foundation for validation through standardized metrics and quality assurance, but cannot provide complete “off-the-shelf” validation reports. Each institution must perform their own validation according to their specific regulatory requirements and risk assessment.
A simplistic diagram of what you as a user intending to work under regulation would provide compared to what nf-core can provide you with is outlined below in the figure:
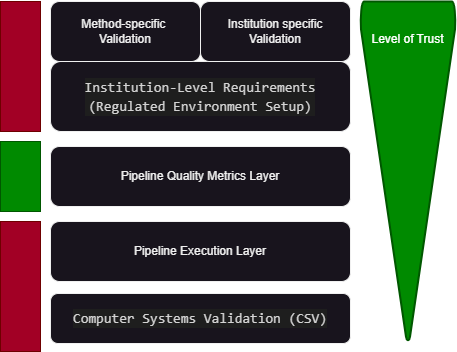
nf-core metrics and reporting system
nf-core/stats service
The nf-core/stats service serves as the central repository for collecting, storing, and analyzing pipeline quality metrics. This system automatically:
- Tracks pipeline metrics across all nf-core pipelines and releases
- Monitors community engagement (contributors, users, issue resolution)
- Assesses code quality (testing coverage, documentation completeness)
- Evaluates pipeline maturity (release history, stability indicators)
- Provides historical data for trend analysis and continuous improvement
Automated validation reports
Each nf-core pipeline release automatically generates a comprehensive PDF validation readiness report containing:
Pipeline overview
- Release information and semantic versioning details
- Community metrics (contributors, users, maintenance activity)
- Licensing and governance information
Quality metrics
- Testing coverage: Functional and integration test results
- Documentation quality: Completeness and clarity assessments
- Code quality: Linting, standards compliance, security scanning
- Dependency management: Tool versions, container specifications
Community indicators
- Maintenance activity: Issue resolution rates, update frequency
- User adoption: Download statistics, citation metrics
- Contributor engagement: Review processes, contribution patterns
Risk assessment factors
- Complexity analysis: Pipeline complexity scoring
- Stability indicators: Error rates, failure patterns
- Change management: Update frequency and impact analysis
Gap identification and improvement
The nf-core community continuously evaluates and enhances the metrics collection system:
- Community feedback: Regular review of validation requirements across different domains
- Standards evolution: Adaptation to changing regulatory landscapes
- Metric enhancement: Addition of new quality indicators based on community needs
- Tooling development: Improvement of automated collection and reporting systems
To request additional metrics or report enhancements, please engage with the regulatory special interest group or open an issue in the nf-core/stats repository.
Regulatory context
Risk-based validation principles
Pipeline validation follows risk-based approaches that consider the development, implementation, and integration of analysis pipelines as potential sources of risk. Common risks include:
- Execution failures: Risk of pipeline not producing expected outputs
- Data integrity: Risk of data corruption or loss during processing
- Analytical accuracy: Risk of incorrect or inconsistent results
- Reproducibility: Risk of inability to replicate results across runs
- Security: Risk of unauthorized access or data breaches
These risks are mitigated through appropriate measures such as comprehensive testing, documentation, version control, and quality assurance processes.
Applicable standards
Regulatory requirements vary by jurisdiction and intended use. Common standards that may apply to bioinformatics pipelines include:
Software as Medical Device (SaMD)
Laboratory Developed Tests (LDT)
Medical device registration
Harmonization efforts
Computerized Systems Validation (CSV) requirements for infrastructure and IT systems are outside the scope of this guidance. Please consult with your IT and compliance teams for CSV requirements.
Using nf-core validation reports
Interpreting the automated reports
The validation readiness reports provide a standardized foundation for institutional validation. Key sections to review include:
1. Executive summary
- Overall pipeline maturity score
- Critical risk indicators
- Recommended validation approach
2. Quality metrics analysis
- Testing coverage and pass rates
- Documentation completeness scores
- Code quality indicators
- Community engagement metrics
3. Risk assessment matrix
- Identified risk factors specific to the pipeline
- Severity and likelihood assessments
- Recommended mitigation strategies
4. Compliance readiness
- Alignment with common regulatory requirements
- Gap analysis for specific use cases
- Documentation and traceability indicators
Institution-specific validation process
Using the nf-core report as a foundation, institutions should follow these steps:
Phase 1: Initial assessment
- Review nf-core validation report for the target pipeline version
- Define intended use and applicable regulatory requirements
- Conduct risk assessment based on institutional context
- Identify validation scope and required evidence
Phase 2: Gap analysis
- Compare nf-core metrics against institutional requirements
- Identify additional testing needs for specific use cases
- Assess infrastructure requirements and CSV considerations
- Plan integration testing with institutional data and systems
Phase 3: Validation execution
- Perform functional verification in target environment
- Execute integration testing with representative datasets
- Validate analytical performance against established criteria
- Document evidence of compliance and performance
Phase 4: Ongoing maintenance
- Monitor pipeline updates and assess impact
- Maintain validation status through change control
- Update validation as requirements evolve
- Participate in community feedback and improvement
Infrastructure considerations
Computing environment
- Reproducibility: Ensure consistent execution across runs
- Security: Implement appropriate access controls and audit trails
- Performance: Validate pipeline performance under expected loads
- Backup/Recovery: Establish data protection and recovery procedures
Data management
- Input validation: Verify data integrity and format compliance
- Output verification: Confirm expected outputs and quality metrics
- Traceability: Maintain complete audit trails of data processing
- Retention: Implement appropriate data retention policies
The nf-core validation report provides a foundation, but each institution must validate the pipeline within their specific environment, with their data, and according to their regulatory requirements.
Community standards and guidelines
Pipeline quality requirements
All nf-core pipelines must meet standardized quality criteria that support validation efforts:
Development standards
- Semantic versioning: Clear version management with defined backward compatibility Semantic Versioning Guideline
- Code quality: Adherence to coding standards and automated linting Linting Guideline
- Testing framework: Comprehensive functional and integration tests
- Documentation: Complete usage instructions and parameter documentation Docs Guideline
Change management
- Pull request process: Mandatory peer review for all changes Release Pull Request guideline
- Automated testing: CI/CD pipeline validation for every change CI Testing Guidelines
- Release process: Structured release workflow with quality checkpoints Release Process guideline
- Issue tracking: Transparent bug reporting and feature request management (entirely open, on respective Github repository of each pipeline)
Security and compliance
- Dependency management: Fixed software versions in containerized environments Software containerization guidelines
- Vulnerability scanning: Regular security assessment of dependencies (responsibility of user/institution, as not easily generalizable). Containers hosted at Seqera Containers are automatically scanned.
- License compliance: Clear licensing for all components Licence Guidelines
- Access control: Controlled access to pipeline repositories and releases Governance at nf-core
Testing framework
nf-core provides comprehensive testing at multiple levels to ensure pipeline quality. Some aspects however are too specific to individual methodology, institutional requirements, so these are not covered by the nf-core community per se. Particularly the integration testing and performance testing of nf-core pipelines is considered out of scope for the regulatory readiness documentation for each pipeline as this is highly dependent on the individual infrastructure and thus falls under either Computer Systems Validation (CSV) and/or local integration.
Functional testing
- Module tests: Validate individual pipeline components using nf-test
- Subworkflow tests: Test combined modules and workflow sections
- Pipeline tests: End-to-end testing with multiple test profiles
- Regression testing: Automated testing to prevent functional regressions
Performance testing
- Resource usage: Monitor computational requirements and efficiency
- Scalability: Test pipeline performance across different dataset sizes
- Benchmarking: Track performance metrics over time
Integration testing
- Environment testing: Validate execution across different computing environments
- Data format testing: Ensure compatibility with various input formats
- Output validation: Verify expected outputs and quality metrics
Documentation standards
Comprehensive documentation supports validation and ensures consistent usage:
User documentation
- Usage instructions: Clear step-by-step execution guidance
- Parameter documentation: Complete description of all configurable options
- Output documentation: Description of all pipeline outputs and their interpretation
- Troubleshooting guides: Common issues and resolution strategies
Technical documentation
- Architecture overview: Pipeline structure and workflow design
- Module documentation: Individual component specifications
- Dependency documentation: Complete list of software dependencies and versions
- Configuration guidelines: Environment setup and configuration requirements
Implementation guidance
Validation process overview
The validation process for nf-core pipelines follows a structured approach across five key phases:
1. Preparation phase
Begin by obtaining the nf-core validation readiness report for your target pipeline version. Define your intended use case and identify applicable regulatory requirements (e.g., FDA SaMD, CLIA, CE Mark, LDT). Assemble a validation team with appropriate expertise and establish validation protocols and acceptance criteria aligned with your institutional needs.
2. Risk assessment
Review the risk indicators provided in the nf-core validation report and conduct an institution-specific risk analysis. Identify critical control points related to execution failures, data integrity, analytical accuracy, reproducibility, and security. Document your risk mitigation strategies and establish ongoing monitoring procedures appropriate for your risk profile.
3. Validation execution
Set up your validated computing environment and execute the nf-core test profiles to verify functional performance. Perform integration testing with institutional data and validate analytical performance against your established specifications. Document all testing evidence and results comprehensively to support your validation package.
4. Operational validation
Establish standard operating procedures (SOPs) for consistent pipeline operation, train personnel on validated procedures, and implement quality control measures. Set up data management and retention procedures, and create incident response and change control processes appropriate for your regulatory context.
5. Ongoing maintenance
Monitor pipeline updates and security advisories from the nf-core community. Assess the impact of changes through your change control process, maintain validation status through periodic review, and update procedures as requirements evolve. Participate in community feedback to contribute to continuous improvement.
For a detailed, actionable checklist covering each phase of the validation process, refer to the Pipeline Validation Checklist.
Gap analysis and improvement
Identifying validation gaps
- Regulatory requirements: Compare nf-core metrics against specific compliance needs
- Technical requirements: Assess infrastructure and integration requirements
- Analytical requirements: Evaluate performance specifications and acceptance criteria
- Documentation requirements: Identify additional documentation needs
Improvement pathways
- Community engagement: Participate in nf-core regulatory working groups
- Metric enhancement: Propose additional metrics through nf-core/stats
- Documentation contributions: Contribute to pipeline documentation and guides
- Testing contributions: Develop and share additional test cases
Maintenance and continuous improvement
Change management
- Version updates: Systematic evaluation of pipeline updates
- Impact Assessment: Risk-based analysis of changes
- Re-validation: Appropriate level of testing for changes
- Documentation Updates: Maintain current validation documentation
Quality monitoring
- Performance tracking: Monitor pipeline performance over time
- Issue resolution: Track and resolve validation-related issues
- Trend analysis: Analyze patterns in pipeline usage and performance
- Continuous improvement: Regular review and enhancement of validation processes
By following this structured approach and leveraging nf-core’s comprehensive metrics and reporting system, institutions can efficiently validate nf-core pipelines while maintaining the flexibility to meet their specific regulatory and operational requirements.